探索信用评分模型的公平性指标
这个例子展示了如何计算和显示两个敏感属性的公平性指标。您可以使用这些指标来测试数据和模型的公平性,然后确定应用于您的情况的阈值。您还可以使用这些度量来理解模型中的偏差、组之间的差异水平,以及如何评估模型的公平性。此示例使用fairnessMetrics“统计和机器学习工具箱”中的类
计算、显示和绘制各种公平指标。
公平指标计算
公平性指标是一组度量,它使您能够检测数据或模型中存在的偏差。偏见指的是一个群体对另一个群体的或隐或显的偏好。当您检测到数据或模型中的偏差时,您可以决定采取措施来减轻偏差。偏见检测是一套能让你看到对一个或另一个群体的不公平存在的措施。偏差缓解是一组工具,用于减少当前分析数据或模型中出现的偏差量。
有一组用于数据的度量,也有一组用于模型的度量。群体指标衡量的是群体内部的信息,而偏见指标衡量的是群体之间的差异。该示例在数据级别计算两个偏差度量(统计奇偶性差(SPD)和差异影响(DI))和一个组度量(组计数)。在本例中,您在模型级别计算4个偏差度量和17个组度量。
偏差指标:
统计奇偶性差异(SPD)衡量的是大多数和受保护阶层获得有利结果的差异。这个量必须等于0才公平。
差异影响(DI)比较了两个组(多数组和少数组)获得有利结果的个体比例。这个量必须等于1才公平。
均等机会差(EOD)衡量的是对机会平等的偏离,这意味着每个群体中相同比例的人得到了有利的结果。这个量必须等于0才公平。
平均绝对比值差(AAOD)通过假阳性率和真阳性率来衡量偏倚。这个量必须等于0才公平。
组指标:
真阳性(TP)是模型正确预测阳性类别的结果总数。
真负(TN)是模型正确预测负类的结果总数。
假阳性(FP)是模型错误预测阳性类别的结果总数。
假阴性(FN)是模型错误预测阴性类别的结果总数。
真阳性率(TPR)是指敏感性。
真阴性率(TNR)是特异性或选择性。
假阳性率(FPR)是一类错误。
假负率(FNR)是第二类误差。
假发现率(FDR)是假阳性结果的数量与总阳性检测结果的数量之比。
假遗漏率(FOR)是预测值为负值而真实标签为正值的个体数量之比。
阳性预测值(Positive Predictive Value, PPV)是真阳性数量与真阳性和假阳性数量之比。
阴性预测值(Negative Predictive Value, NPV)是真阴性的数量与真阳性和假阳性的数量之比。
阳性预测率(RPP)或接受率是假阳性和真阳性的数量与总观察数的比率。
阴性预测率(RNP)是假阴性数和真阴性数与总观察数之比。
准确度(ACC)是真阴性和真阳性的数量与总观测量的比率。
群体数量是群体中的个体数量。
群体规模比是群体中的个体数量与总个体数量的比率。
该示例重点关注信用卡数据中的偏见检测,并探索基于客户年龄的敏感属性的偏见度量和分组度量(CustAge)及居民身分(ResStatus).数据包含居住状态作为分类变量,客户年龄作为数字变量。为了创建预测和分析数据的公平性,您可以将客户年龄变量分组到多个箱子中。
可视化信用卡数据中的敏感属性
加载信用卡数据集。将顾客年龄分组到不同的箱子中。使用离散化函数的一个数值变量,该变量创建的组标识感兴趣的年龄组,以进行公平性比较。检索客户年龄和居住状态这两个敏感属性的计数。
负载CreditCardData.matAgeGroup =离散化(data.CustAge,[min(data.CustAge) 30 45 60 max(data.CustAge)],...“分类”, {“< 30岁”,“30岁<=年龄< 45岁”,'45 <=年龄< 60',“年龄> = 60岁”});data = addvars(数据、伙伴,“后”,“CustAge”);gs_data_ResStatus = groupsummary(数据,{“ResStatus”,“状态”});gs_data_AgeGroup = groupsummary(数据,{“伙伴”,“状态”});
画出按年龄划分的信用卡拖欠和未拖欠的客户数量。
属性=“伙伴”;图酒吧(独特(数据(属性),...(eval (“gs_data_”+属性+“.GroupCount(1:2结束):“),...eval (“gs_data_”+属性+“.GroupCount(2:2结束):“)]);标题(属性+“真正的价值”);ylabel (“计数”)({传奇“默认”,“违约”})


计算数据的公平性指标
计算住宅状况和客户年龄数据的公平性指标。的fairnessMetrics返回一个类fairnessMetrics对象,然后将该对象传递到报告方法获取带有偏差度量和组度量的表。偏差度量同时考虑两个类(多数和少数),而组度量则在单个组内。在数据集中,如果使用居住状态作为敏感属性,则房主群体是多数类,因为这个类包含最多的个体。基于SPD和DI指标,数据集没有显示出对居住状态的显著偏见。对于客户年龄数据,45到60岁之间的年龄组是大多数的类别,因为这个类别包含的个人数量最多。基于SPD和DI指标,与居住状态相比,年龄大于60岁的群体偏倚的存在略大。
dataMetricsObj = fairnessMetrics(数据,“状态”,“SensitiveAttributeNames”, {“ResStatus”,“伙伴”})
dataMetricsObj = fairnessMetrics with properties: SensitiveAttributeNames: {'ResStatus' 'AgeGroup'} ReferenceGroup: {'Home Owner' '45 <= Age < 60'} ResponseName: 'status' PositiveClass: 1 BiasMetrics: [7x4 table] GroupMetrics: [7x4 table]
dataMetricsTable =报告(dataMetricsObj,“GroupMetrics”,“GroupCount”)
dataMetricsTable =7×5表SensitiveAttributeNames Groups StatisticalParityDifference DisparateImpact GroupCount _______________________ ______________ ___________________________ _________________________ ResStatus Home Owner 0 1 542 ResStatus Tenant 0.025752 1.0789 474 ResStatus Other -0.038525 0.88203 184 AgeGroup Age < 30 0.0811 1.2759 64 AgeGroup 30 <= Age < 45 0.10333 1.3516 506 AgeGroup 45 <= Age < 60 0 1 541 AgeGroup Age >= 60 -0.14783 0.497 89
创建信用记分卡模型并生成预测
方法创建信用记分卡模型creditscorecard函数。方法对预测器执行自动分组autobinning函数。拟合逻辑回归模型的证据权重(祸)数据使用fitmodel函数。将预测器名称和相应系数存储在信用记分卡模型中。
PredictorVars = setdiff (data.Properties.VariableNames,...{“伙伴”,“CustID”,“状态”});sc = creditscorecard(数据,“IDVar”,“CustID”,...“PredictorVars”, PredictorVars);sc = autobinning (sc);sc = fitmodel (sc);
1.添加CustIncome, Deviance = 1490.8527, Chi2Stat = 32.588614, PValue = 1.1387992e-082 .添加TmWBank, Deviance = 1467.1415, Chi2Stat = 23.711203, PValue = 1.1192909e-063 .添加AMBalance, Deviance = 1455.5715, Chi2Stat = 11.569967, PValue = 0.00067025601。4 .添加EmpStatus, Deviance = 1447.3451, Chi2Stat = 8.2264038, PValue = 0.0041285257。5.添加CustAge, Deviance = 1441.994, Chi2Stat = 5.3511754, PValue = 0.020708306。7.添加ResStatus, Deviance = 1437.8756, Chi2Stat = 4.118404, PValue = 0.042419078。添加OtherCC, Deviance = 1433.707, Chi2Stat = 4.1686018, PValue = 0.041179769广义线性回归模型:状态~[7个预测因子中有8项的线性公式]分布=二项估计系数:估计SE tStat pValue ________ ________ ______ __________ (Intercept) 0.70239 0.064001 10.975 5.0538e-28 CustAge 0.60833 0.24932 2.44 0.014687 ResStatus 1.377 0.65272 2.1097 0.034888 EmpStatus 0.88565 0.293 3.0227 0.0025055 CustIncome 0.70164 0.21844 3.2121 0.0013179 TmWBank 1.1074 0.23271 4.7589 1.9464e-06 OtherCC 1.0883 0.52912 2.0569 0.039696 AMBalance 1.045 0.32214 3.2439 0.0011792 1200观察,1192误差自由度色散:1 Chi^2-统计与常数模型:89.7, p-value = 1.4e-16
控件显示模型中保留的预测器的未缩放点displaypoints函数。
pointsinfo = displaypoints (sc)
pointsinfo =37×3表预测本点 ______________ ________________ _________ {' CustAge’}{[无穷,33)的-0.15894}{‘CustAge}{[33岁,37)的-0.14036}{‘CustAge}{[37、40)的-0.060323}{‘CustAge}{[40岁,46)的0.046408}{‘CustAge}{[46岁,48)的0.21445}{‘CustAge}{[48, 58)的0.23039}{“CustAge”}{的[58岁的Inf]} 0.479{‘CustAge}{“失踪> <”}南{‘ResStatus}{“租户”}-0.031252{‘ResStatus}{‘业主’}0.12696{‘ResStatus}{‘其他’}0.37641{‘ResStatus}{“失踪> <”}南{' EmpStatus '}{'Unknown'} -0.076317 {'EmpStatus'} {'Employed'} 0.31449 {'EmpStatus'} {''} NaN {'CustIncome'} {'[-Inf,29000)'} -0.45716
有关创建更深入的信用评分模型的详细信息,请参见使用Bin Explorer创建信用记分卡.
计算信用记分卡模型的违约概率probdefault函数。将违约概率的阈值定义为0.35。创建一个预测数组,其中每个值都大于阈值。
pd = probdefault (sc);阈值= 0.35;预测=双(pd) >阈值;
将得到的预测结果添加到数据输出表。要计算偏差指标,可以留出一组验证数据。检索居住状态和客户年龄预测的计数。绘制客户年龄预测图。
data = addvars(数据、预测,“后”,“状态”);gs_predictions_ResStatus = groupsummary(数据,{“ResStatus”,“预测”},...“IncludeEmptyGroups”,真正的);gs_predictions_AgeGroup = groupsummary(数据,{“伙伴”,“预测”},...“IncludeEmptyGroups”,真正的);属性=“伙伴”;图酒吧(独特(数据(属性),...(eval (“gs_predictions_”+属性+“.GroupCount(1:2结束):“),...eval (“gs_predictions_”+属性+“.GroupCount(2:2结束):“)]);标题(属性+“预测数”);ylabel (“计数”)({传奇“默认”,“违约”})


计算和可视化信用记分卡模型的公平指标
计算模型偏差和群体指标的居住状况和客户年龄。对于DI模型度量,通常用于评估公平性的范围在0.8到1.25之间[3.].小于0.8的值表示存在偏差。但是,如果值大于1.25,则表示有些事情不正确,可能需要进行额外的调查。本例中的模型偏差指标比数据偏差指标对公平性的影响更大。模型拟合后,SPD和EOD值为负表示其他组显示出轻微的偏见。在群体指标中,租户的FPR组指标为39.7%,高于房屋所有者,这意味着租户更容易被错误地标记为违约者。FDR、FOR、PPV和NPV组指标显示出非常小的偏差存在。
看看客户年龄的模型偏差度量SPD、DI、EOD和AAOD, 30岁及以下的群体与多数群体的差异最大,可能需要进一步调查。此外,60岁以上年龄组的SPD和EOD值为负值,DI值极低,显示出偏倚的存在。此外,基于DI指标,可能需要额外的模型偏差缓解。
在群体指标中,30岁及以下人群的FPR指标为80%,远远高于多数人群,这意味着30岁及以下人群更容易被错误地贴上违约标签。FDR组的指标为83.3%,这在60岁以上的人群中远远高于大多数人群,这意味着在年龄超过60岁且被模型识别为违约的人群中,有83.3%为假阳性。的精度Metric显示60岁以上人群的准确率最高,为80.9%。
modelMetricsObj = fairnessMetrics(数据,“状态”,“SensitiveAttributeNames”, {“ResStatus”,“伙伴”},“预测”预测)
modelMetricsObj = fairnessMetrics with properties: SensitiveAttributeNames: {'ResStatus' 'AgeGroup'} ReferenceGroup: {'Home Owner' '45 <= Age < 60'} ResponseName: 'status' PositiveClass: 1 BiasMetrics: [7x6 table] GroupMetrics: [7x19 table]
modelMetricsTable =报告(modelMetricsObj,“GroupMetrics”,“所有”)
modelMetricsTable =表7×23敏属性名组统计particaldifference差异差异均等机会差异平均绝对oddsdifference GroupCount GroupSizeRatio真阳性真阴性假阳性假阴性真阳性真阳性假阳性假阴性假阴性假发现率假遗漏率正阳性预测值负阳性预测值正阳性预测率负阳性预测精度_______________________ ______________ __________________________________________ __________________________ _____________________________ __________ ______________ _____________ _____________ ______________ ______________ ________________ ________________ _________________ _________________ __________________ _________________ _______________________ _______________________ _________________________ _________________________ ________ ResStatus房主0 1 0 0 542 88 252 113 89 0.49718 0.45167 0.69041 0.30959 0.50282 0.56219 0.261 0.43781 0.739 0.370850.62915 0.62731 ResStatus Tenant 0.10173 1.2743 0.1136 0.1007 474 0.395 102 185 122 65 0.61078 0.60261 0.39739 0.39739 0.54464 0.74 0.47257 0.52743 0.60549 ResStatus Other -0.11541 0.68878 -0.082081 0.10042 184 0.15333 22 106 25 31 0.41509 0.80916 0.19084 0.58491 0.53191 0.22628 0.46809 0.77372 0.25543 0.74457 0.69565 AgeGroup Age < 30 0.55389 3.4362 0.41038 0.51433 18 8 32 6 0.75 0.2 0.8 0.25 0.55 0.42857 0.36 0.57143 0.78125 0.21875 0.40625 AgeGroup 30 <= Age < 450.35169 2.5469 0.3381 506 0.42167 139 151 154 62 0.69154 0.49508 0.50492 0.30846 0.5256 0.29108 0.4744 0.70892 0.57905 0.42095 0.57312年龄组45 <=年龄< 60 0 10 0 541 0.45083 54 313 69 105 0.33962 0.81937 0.18063 0.66038 0.56098 0.2512 0.43902 0.7488 0.22736 0.77264 0.67837年龄组年龄>= 60 -0.15994 0.29652 -0.2627 0.18877 89 0.065789 0.93321 0.14458 0.16667 0.85542 0.067423 0.93258 0.80899
选择偏差度量和敏感属性并绘制。这段代码选择AAOD而且的伙伴默认情况下。
BiasMetric =“AverageAbsoluteOddsDifference”;SensitiveAttribute =
“伙伴”;情节(modelMetricsObj BiasMetric,“SensitiveAttributeNames”, SensitiveAttribute);


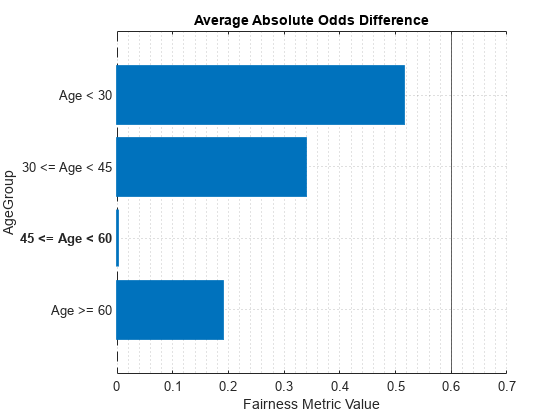
对于相同的敏感属性,选择组度量并绘制它。这段代码默认选择组数。结果图显示了所选敏感属性的度量值。
GroupMetric =“GroupCount”;情节(modelMetricsObj GroupMetric,“SensitiveAttributeNames”, SensitiveAttribute);

绘制两个敏感属性的SPD、DI、EOD和AAOD偏差度量。
MetricsShort = [“社会民主党”“迪”“爆炸品处理”“aaod”];tiledlayout(2、4)

为sa =字符串(modelMetricsObj.SensitiveAttributeNames)为h = plot(modelMetricsObj,m,“SensitiveAttributeNames”、sa);标题(h.Parent,上层(m));h.Parent.XLabel = [];如果m ~ = MetricsShort (1) h.Parent.YTickLabel =”;h.Parent.YLabel = [];结束结束结束

偏差保持指标寻求保持目标模型输出的历史性能,对训练数据中显示的每组具有相同的错误率。这些指标并不能改变存在于社会中的现状。当一个完美分类器完全满足公平性度量时,公平性度量被归为保留偏差。相反,偏差转换指标要求明确决定系统应该显示哪些偏差。这些指标不接受现状,承认保护组从不同的不平等的点开始。这两种类型的度量之间的主要区别是,大多数偏差转换度量是通过匹配组之间的决策率来满足的,而偏差保留度量则需要匹配错误率。为了评估决策系统的公平性,使用偏差保留和转换度量来创建系统中偏差的最广泛的视图。
用一个完美的分类器来评估一个度量是否保持偏倚是很简单的。在没有完美分类器的情况下,可以用分类器响应代替预测,并观察公式是否基本正确。EOD和AAOD是保留偏差的指标,因为它们没有方差;然而,SPD和DI是偏差转换指标,因为它们显示了与大多数类的差异。
biasMetrics_ResStatus1Obj = fairnessMetrics(数据,“状态”,“SensitiveAttributeNames”,“ResStatus”,“预测”,“状态”);报告(biasMetrics_ResStatus1Obj)
ans =3×6表SensitiveAttributeNames组StatisticalParityDifference DisparateImpact EqualOpportunityDifference AverageAbsoluteOddsDifference _______________________ __________ ___________________________ _______________ __________________________ _____________________________ ResStatus房主0 1 0 0 ResStatus租户0.025752 - 1.0789 0 0 ResStatus其他-0.038525 - 0.88203 0 0
biasMetrics_AgeGroup1Obj = fairnessMetrics(数据,“状态”,“SensitiveAttributeNames”,“伙伴”,“预测”,“状态”);报告(biasMetrics_AgeGroup1Obj)
ans =4×6表SensitiveAttributeNames组StatisticalParityDifference DisparateImpact EqualOpportunityDifference AverageAbsoluteOddsDifference _______________________ ______________ ___________________________ _______________ __________________________ _____________________________ 伙伴年龄< 30 0.0811 - 1.2759 0 0的伙伴30 < = < 45岁0.10333 - 1.3516 0 0的伙伴45 < =年龄< 60 0 1 0 0的伙伴年龄> = 60 0 0 -0.14783 - 0.497
参考文献
Schmidt, Nicolas, Sue Shay, Steve Dickerson, Patrick Haggerty, Arjun R. Kannan, Kostas Kotsiopoulos, Raghu Kulkarni, Alexey Miroshnikov, Kate Prochaska, Melanie Wiwczaroski, Benjamin Cox, Patrick Hall和Josephine Wang。机器学习:公平透明地扩大信贷准入的考虑。加州山景城:H2O。ai公司,2020年7月。
Mehrabi, Ninareh等人,《关于机器学习中的偏见和公平的调查》。ArXiv: 1908.09635 (Cs)2019年9月。arXiv.org,https://arxiv.org/abs/1908.09635.
Saleiro, Pedro等人,《Aequitas:偏见和公平审计工具包》。ArXiv: 1811.05577 (Cs), 2019年4月。arXiv.org,https://arxiv.org/abs/1811.05577.
Wachter, Sandra等人。机器学习中的偏见保存:欧盟非歧视法下公平度量的合法性.学术论文,社会科学研究网,ID 3792772, 2021年1月15日。papers.ssrn.com,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3792772.
另请参阅
creditscorecard|autobinning|fitmodel|displaypoints|probdefault
相关的话题
您也可以从以下列表中选择网站: