通过消除差异影响来减轻信用评分中的偏见
异类影响消除是偏差缓解中的一种预处理技术。使用这种技术,您可以修改原始信用评分数据以增加组的公平性,同时仍然保留组内的排名顺序。与使用原始数据训练信用评分模型相比,使用异类影响去除技术可以更有效地减少信用评分模型引入的偏差。方法执行不同影响消除技术disparateImpactRemover类从统计和机器学习工具箱™。这个类返回一个剂对象以及包含新的预测器值的表。但是,您需要使用变换方法与剂对象上的测试数据,才能使用拟合的信用评分模型进行预测。
差异影响消除技术仅适用于敏感属性的每个子组的数字预测器中的数据分布。的disparateImpactRemover类不知道响应变量,也不与响应变量相关。在本例中,处理所有的数值预测器,time at address (TmAtAddress)、客户收入(CustIncome),与银行的时间(TmWBank)、每月平均结余(AMBalance)和使用率(UtilRate),就敏感属性而言,客户年龄(的伙伴).
原始信用评分模型
这个例子使用了一个信用评分工作流。加载CreditCardData.mat并使用“数据”数据集。
负载CreditCardData.matAgeGroup =离散化(data.CustAge,[min(data.CustAge) 30 45 60 max(data.CustAge)],...“分类”,{“< 30岁”,“30岁<=年龄< 45岁”,'45 <=年龄< 60',“年龄> = 60岁”});data = addvars(数据、伙伴,“后”,“CustAge”);头(数据)
CustID CustAge伙伴TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate地位 ______ _______ ______________ ___________ __________ _________ __________ _______ _______ _________ ________ ______ 1 53 45 < =年龄< 60 62租户未知50000 55是的1055.9 - 0.22 0 2 61年龄> = 60 22家老板雇用了52000名25是的1161.6 - 0.24 0 3 45 < = 47年龄< 60岁30租户使用45 37000 61没有877.23 - 0.29 0 4 50 < =年龄< 60 75业主雇用了53000名20是的157.37 - 0.08 0 5 68的年龄>= 60 56屋主受雇53000 14是561.84 0.11 0 6 65年龄>= 60 13屋主受雇48000 59是968.18 0.15 0 7 34 30 <=年龄< 45 32屋主未知32000 26是717.82 0.02 18 50 45 <=年龄< 60 57其他受雇51000 33否3041.2 0.13 0
rng (“默认”)
将数据集拆分为训练和测试数据。
c = cvpartition(大小(数据,1),“坚持”, 0.3);: data_Train =数据(c.training ());: data_Test =数据(让());头(data_Train)
CustID CustAge伙伴TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate地位 ______ _______ ______________ ___________ __________ _________ __________ _______ _______ _________ ________ ______ 1 53 45 < =年龄< 60 62租户未知50000 55是的1055.9 - 0.22 0 2 61年龄> = 60 22家老板雇用了52000名25是的1161.6 - 0.24 0 3 45 < = 47年龄< 60岁30租户使用45 37000 61没有877.23 - 0.29 0 4 50 < =年龄< 60 75业主雇用了53000名20是的157.37 - 0.08 0 7 34 30 < =Age < 45 32 Home Owner Unknown 32000 26 Yes 717.82 0.02 1 8 50 45 <= Age < 60 57 Other Employed 51000 33 No 3041.2 0.13 0 9 50 45 <= Age < 60 10 Tenant Unknown 52000 25 Yes 115.56 0.02 1 10 49 45 <= Age < 60 30 Home Owner Unknown 53000 23 Yes 718.5 0.17 1
使用creditscorecard创建一个creditscorecard对象和使用fitmodel用训练数据拟合信用评分模型(data_Train).
PredictorVars = setdiff (data_Train.Properties.VariableNames,...{“CustAge”,“伙伴”,“CustID”,“状态”});那么= creditscorecard (data_Train,“IDVar”,“CustID”,...“PredictorVars”PredictorVars,“ResponseVar”,“状态”);那么= autobinning(那么);那么= fitmodel(那么,“VariableSelection”,“fullmodel”);
广义线性回归模型:状态~[8个预测因子中9项的线性公式]分布=二项估计系数:估计SE tStat pValue ________ ________ ________ __________ (Intercept) 0.73924 0.077237 9.5711 1.058e-21 TmAtAddress 1.2577 0.99118 1.2689 0.20448 ResStatus 1.755 1.295 1.3552 0.17535 EmpStatus 0.88652 0.32232 2.7504 0.0059516 CustIncome 0.95991 0.19645 4.8862 1.0281e-06 TmWBank 1.132 0.3157 3.5856 0.00033637 OtherCC 0.85227 2.1198 0.40204 0.68765 AMBalance 1.0773 0.31969 3.3698 0.00075232 UtilRate -0.19784 0.59565 -0.33214 0.73978 840观察,831误差自由度色差:1 Chi^2统计量与常数模型:66.5,p-value = 2.44e-11
使用displaypoints计算每个预测器和每个容器的点数creditscorecard模型(那么).
pointsinfo1 = displaypoints(那么)
pointsinfo1 =38×3表预测本点 _______________ _________________ _________ {' TmAtAddress’}{[负9)的-0.17538}{‘TmAtAddress}{[9、16)的0.05434}{‘TmAtAddress}{[16日,23)的0.096897}{‘TmAtAddress}{[23岁,正]的}0.13984{‘TmAtAddress}{“失踪> <”}南{‘ResStatus}{“租户”}-0.017688{‘ResStatus}{‘业主’}0.11681{‘ResStatus}{‘其他’}0.29011{‘ResStatus}{“失踪> <”}南{‘EmpStatus}{‘未知’}-0.097582{‘EmpStatus}{“雇佣”}0.33162{‘EmpStatus}{< >失踪的}NaN {'CustIncome' } {'[-Inf,30000)' } -0.61962 {'CustIncome' } {'[30000,36000)'} -0.10695 {'CustIncome' } {'[36000,40000)'} 0.0010845 {'CustIncome' } {'[40000,42000)'} 0.065532 ⋮
使用probdefault以确定违约的可能性data_Test数据集和creditscorecard模型(那么).
pd1 = probdefault(那么,data_Test);阈值= 0.35;双(pd1 predictions1 = >阈值);
使用fairnessMetrics在模型级别上计算公平性指标作为基线。使用报告生成公平指标报告。
modelMetrics1 = fairnessMetrics (data_Test,“状态”,“预测”predictions1,“SensitiveAttributeNames”,“伙伴”);mmReport1 =报告(modelMetrics1,“GroupMetrics”,“GroupCount”)
mmReport1 =表4×7SensitiveAttributeNames组StatisticalParityDifference DisparateImpact EqualOpportunityDifference AverageAbsoluteOddsDifference GroupCount _______________________ ______________ ___________________________ _______________ __________________________ _____________________________ __________ < 30岁的伙伴0.54312 2.6945 0.47391 0.5362 22的伙伴30 < =年龄< 45 0.19922 1.6216 0.35645 0.22138 152伙伴45 < =年龄< 60 0 1 0 0 156的伙伴年龄> = 30 60 -0.15385 0.52 -0.18323 0.16375
使用情节要可视化统计奇偶性差异(“社会民主党”)和不同的影响(“迪”)偏差指标。
图tiledlayout(2,1) nexttile plot(modelMetrics1,“社会民主党”) nexttile情节(modelMetrics1“迪”)

通过消除异类影响减少偏差
对于五个连续预测因子中的每一个,”TmAtAddress””,CustIncome”,“TmWBank”,“AMBalance”,“UtilRate”绘制出每个年龄组数据的原始分布。
选择一个数字预测器来绘制。
预测=“CustIncome”;[f1, xi1] = ksdensity(data_Train.(predictor)(data_Train. agegroup ==“< 30岁”));[f2, xi2] = ksdensity(data_Train.(predictor)(data_Train. agegroup ==“30岁<=年龄< 45岁”));[f3, xi3] = ksdensity(data_Train.(predictor)(data_Train. agegroup =='45 <=年龄< 60'));[f4, xi4] = ksdensity(data_Train.(predictor)(data_Train. agegroup ==“年龄> = 60岁”));

创建一个disparateImpactRemover对象,并返回newTrainTbl表中包含新的预测器值。
[remover, newTrainTbl] = distateimpactremover (data_Train,“伙伴”,“PredictorNames”, {“TmAtAddress”,“CustIncome”,“TmWBank”,“AMBalance”,“UtilRate”})
remover = distateimpactremover,属性:RepairFraction: 1 PredictorNames: {1x5 cell} SensitiveAttribute: 'AgeGroup'
newTrainTbl =840×12表CustID CustAge伙伴TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate地位 ______ _______ ______________ ___________ __________ _________ __________ _______ _______ _________ ________ ______ 1 53 45 < =年龄< 60岁58.599租户未知47000 51.733对1009.4 - 0.20099 0 2 61年龄> = 60 24业主雇佣了41500 24.5对1203.9 - 0.25 0 3 47 45 < =年龄< 60岁30.5租户使用33500 57.686 817.9 0.29 0 4 50 45 < =年龄< 60岁68.622业主雇佣了49401 19.07是的120.54 0.077267 0 7 34 30 <= Age < 45 30.5 Home Owner Unknown 35500 26.657 Yes 638.88 0.02 1 8 50 45 <= Age < 60 53.39 Other Employed 47000 27.971 No 2172.7 0.12 0 9 50 45 <= Age < 60 9 Tenant Unknown 49401 22.541 Yes 120.54 0.02 1 10 49 45 <= Age < 60 30.5 Home Owner Unknown 49401 22 Yes 664.51 0.14715 1 11 52 45 <= Age < 60 24 Tenant Unknown 30500 38.779 Yes 120.54 0.065 1 12 48 45 <= Age < 60 77.291 Other Unknown 40500 14.5 Yes 405.81 0.03 0 14 44 30 <= Age < 45 68.622 Other Unknown 44500 34.791 No 378.88 0.15657 0 17 39 30 <= Age < 45 9 Tenant Employed 37500 38.779 Yes 664.51 0.25 1 20 52 45 <= Age < 60 51.442 Other Unknown 38500 12.297 Yes 1157.5 0.19273 0 21 37 30 <= Age < 45 10.343 Tenant Unknown 36500 23.314 No 732.28 0.065 1 22 51 45 <= Age < 60 12.087 Home Owner Employed 31500 27.971 Yes 437.95 0.01 0 24 43 30 <= Age < 45 40 Tenant Employed 33500 11.18 Yes 263.13 0.077267 0 ⋮
[nf1, nxi1] = ksdensity(newTrainTbl.(predictor)(newTrainTbl. agegroup ==“< 30岁”));[nf2, nxi2] = ksdensity(newTrainTbl.(predictor)(newTrainTbl. agegroup ==“30岁<=年龄< 45岁”));[nf3, nxi3] = ksdensity(newTrainTbl.(predictor)(newTrainTbl. agegroup =='45 <=年龄< 60'));[nf4, nxi4] = ksdensity(newTrainTbl.(predictor)(newTrainTbl. agegroup ==“年龄> = 60岁”));
绘制原始分布和修复分布。
图;Tiledlayout (2,1) ax1 = nexttile;情节(ξ1,f1,“线宽”, 1.5)在图(2),f2,“线宽”图(xi3, f3,“线宽”图(xi4, f4,“线宽”传说,1.5)([“< 30岁”;30岁<=年龄< 45岁;"45 <=年龄< 60";“年龄> = 60”),“位置”,“西北”) ax1.Title。字符串=“原始分布”+预测;包含(预测)ylabel (“pdf”网格)在ax2 = nexttile;情节(nf1 nxi1,“线宽”, 1.5)在情节(nf2 nxi2,“线宽”, 1.5) plot(nxi3, nf3,“线宽”, 1.5) plot(nxi4, nf4,“线宽”传说,1.5)([“< 30岁”;30岁<=年龄< 45岁;"45 <=年龄< 60";“年龄> = 60”),“位置”,“西北”) ax2.Title。字符串=“修复的分布”+预测;包含(预测)ylabel (“pdf”网格)在linkaxes ([ax₁,ax2],“xy”)
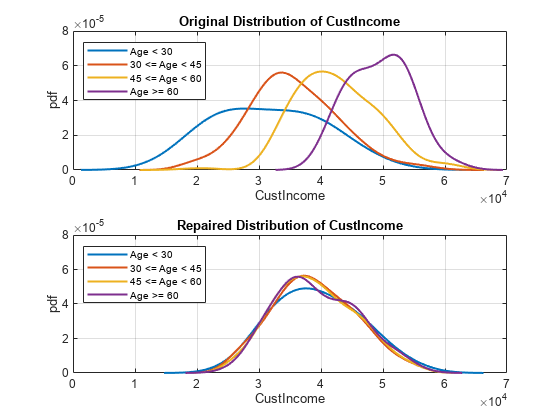
的初始分布CustIncome的每一组的伙伴预测是不同的。年轻人的平均收入似乎比老年人更低,差异也更大。这种差异引入了偏差,然后拟合模型反映了偏差。的disparateImpactRemover函数修改数据,使所有子组的分布更加相似。你可以在第二副图中看到这个分布修复了客户收入的分配.使用这些新数据,您可以拟合一个逻辑回归模型,然后度量模型级指标,并将这些指标与原始的模型级指标进行比较creditscorecard模型(那么).
新的信用评分模型
使用creditscorecard创建一个creditscorecard对象和使用fitmodel为了用新数据拟合信用评分模型(newTrainTbl).然后,您可以使用计算模型级偏差度量fairnessMetrics.
星际2 = creditscorecard (newTrainTbl,“IDVar”,“CustID”,...“PredictorVars”PredictorVars,“ResponseVar”,“状态”);星际2 = autobinning(星际2);星际2 = fitmodel(星际2,“VariableSelection”,“fullmodel”);
广义线性回归模型:状态~[8个预测因子中9项的线性公式]分布=二项估计系数:估计SE tStat pValue _________ _______ _______ __________ (Intercept) 0.74041 0.07641 9.6899 3.327e-22 TmAtAddress 1.1658 0.87564 1.3313 0.18308 ResStatus 1.8719 1.2848 1.4569 0.14513 EmpStatus 0.88699 0.31991 2.7727 0.00556 CustIncome 0.98269 0.28725 0.31991 3.421 0.00062396 TmWBank 1.1392 0.30677 3.7135 0.00020442 OtherCC 0.55005 2.0969 0.26231 0.79308 AMBalance 1.0478 0.3607 2.9049 0.0036734 UtilRate -0.071972 0.58704 -0.1226 0.90242 840观察,831误差自由度色差:1 Chi^2统计量与常数模型:50.4,p值= 3.36e-08
使用displaypoints计算每个预测器和每个容器的点数creditscorecard模型(星际2).
星际2 pointsinfo2 = displaypoints ()
pointsinfo2 =35×3表预测本点 _______________ _________________ _________ {' TmAtAddress’}{[负9)的-0.11003}{‘TmAtAddress}{-0.091424的15.1453(9日)}{‘TmAtAddress}{'[15.1453,正]}0.14546{‘TmAtAddress}{“失踪> <”}南{‘ResStatus}{“租户”}-0.024878{‘ResStatus}{‘业主’}0.11858{‘ResStatus}{‘其他’}0.30343{‘ResStatus}{“失踪> <”}南{‘EmpStatus}{‘未知’}-0.097539{‘EmpStatus}{“雇佣”}0.3319{‘EmpStatus}{“失踪> <”}南{' CustIncome '}-0.30942{[无穷,31500)的}{‘CustIncome}{[31500、38500)的-0.09789}{‘CustIncome}{[38500、45000)的0.21233}{‘CustIncome}{”(45000年,正)}0.494{‘CustIncome}{“失踪> <”}南⋮
在计算测试数据的违约概率之前,您需要使用与训练数据相同的转换来转换测试数据。要进行此转换,请使用变换的方法剂对象并将其传入data_Test数据集。然后,用probdefault计算的违约可能性data_Test数据集。
data_Test newTestTbl =变换(剂);pd2 = probdefault(星际2,newTestTbl);双(pd2 predictions2 = >阈值);
使用fairnessMetrics在模型级计算公平度量并使用报告生成一份公平指标报告。
modelMetrics2 = fairnessMetrics (newTestTbl,“状态”,“预测”predictions2,“SensitiveAttributeNames”,“伙伴”);mmReport2 =报告(modelMetrics2,“GroupMetrics”,“GroupCount”)
mmReport2 =表4×7SensitiveAttributeNames组StatisticalParityDifference DisparateImpact EqualOpportunityDifference AverageAbsoluteOddsDifference GroupCount _______________________ ______________ ___________________________ _______________ __________________________ _____________________________ __________ < 30岁的伙伴0.082751 1.2226 0.18696 0.10408 22的伙伴30 < =年龄< 45 -0.0033738 0.99093 0.07902 0.076333 152伙伴45 < =年龄< 60 0 1 0 0 156的伙伴年龄> = 60 0.028205 1.0759 0.015528 0.02614330.
使用情节要可视化统计奇偶性差异(“社会民主党”)和不同的影响(“迪”)偏差指标。
图tiledlayout(2,1) nexttile plot(modelMetrics2,“社会民主党”) nexttile情节(modelMetrics2“迪”)

绘制不同修理分数值的不同影响和精度图
在本例中,偏差缓解过程使用disparateImpactRemover设置RepairFraction= 1为了减少偏见。但是,看到不同的影响和准确性如何随着的变化而变化是有用的RepairFraction价值。例如,使用的伙伴预测和绘图的不同的影响和准确性的不同子组的不同值RepairFraction.
子群=4;r = 0:0.1:1;精度= 0(11日1);di = 0(11日1);为i = 0:1:10 [rmvr, trainTbl] = distateimpactremover (data_Train,“伙伴”,...“PredictorNames”, {“TmAtAddress”,“CustIncome”,“TmWBank”,“AMBalance”,“UtilRate”},“RepairFraction”,我/ 10);testTbl = transform(rmvr, data_Test);sc = creditscorecard (trainTbl,“IDVar”,“CustID”,...“PredictorVars”PredictorVars,“ResponseVar”,“状态”);sc = autobinning (sc);sc = fitmodel (sc,“VariableSelection”,“fullmodel”,“显示”,“关闭”);pd = probdefault (sc, testTbl);预测=双(pd) >阈值;modelMetrics = fairnessMetrics (newTestTbl,“状态”,“预测”预测,“SensitiveAttributeNames”,“伙伴”);mmReport =报告(modelMetrics,“BiasMetrics”,“迪”,“GroupMetrics”,“准确性”);di (i + 1) = mmReport.DisparateImpact(群);准确性(i + 1) = mmReport.Accuracy(群);结束图yyaxis左情节(r, di,“线宽”, 1.5)标题(“减轻年龄组别的偏见”)包含(“修复分数”) ylabel (的不同影响) yyaxis正确的情节(r,准确性,“线宽”1.5) ylabel (“准确性”网格)在


如果选择子组“< 30岁”从这个图中,你可以看到,随着RepairFraction价值增加。虽然这似乎违反直觉,但进一步看GroupCount这个年龄段的mmReport2这个组只有22个观察结果。少量的观测解释了这幅图中的异常现象。
缓解没有足够数据的子组问题的一种方法是合并所有无特权组,并将它们作为一个组与特权组进行比较。以下代码向您展示如何通过设置多数组(年龄< 60岁)作为特权群体,然后将其他所有群体合并为一个群体,并将该群体设置为非特权群体。
privilegedGroup ='45 <=年龄< 60';twoAgeGroups_TrainTbl = data_Train;twoAgeGroups_TrainTbl。的伙伴= addcats(twoAgeGroups_TrainTbl.AgeGroup,“其他”,“后”,“年龄> = 60岁”);twoAgeGroups_TrainTbl.AgeGroup (twoAgeGroups_TrainTbl。年龄组~= privilegedGroup) =“其他”;twoAgeGroups_TestTbl = data_Test;twoAgeGroups_TestTbl。的伙伴= addcats(twoAgeGroups_TestTbl.AgeGroup,“其他”,“后”,“年龄> = 60岁”);twoAgeGroups_TestTbl.AgeGroup (twoAgeGroups_TestTbl。年龄组~= privilegedGroup) =“其他”;r = 0:0.1:1;精度= 0(11日1);di = 0(11日1);为i = 0:1:10 [rmvr, trainTbl] = distateimpactremover (twoAgeGroups_TrainTbl,“伙伴”,...“PredictorNames”, {“TmAtAddress”,“CustIncome”,“TmWBank”,“AMBalance”,“UtilRate”},“RepairFraction”,我/ 10);testTbl = transform(rmvr, twoAgeGroups_TestTbl);sc = creditscorecard (trainTbl,“IDVar”,“CustID”,...“PredictorVars”PredictorVars,“ResponseVar”,“状态”);sc = autobinning (sc);sc = fitmodel (sc,“VariableSelection”,“fullmodel”,“显示”,“关闭”);pd = probdefault (sc, testTbl);预测=双(pd) >阈值;modelMetrics = fairnessMetrics (twoAgeGroups_TestTbl,“状态”,“预测”预测,...“SensitiveAttributeNames”,“伙伴”,“ReferenceGroup”,'45 <=年龄< 60');mmReport =报告(modelMetrics,“BiasMetrics”,“迪”,“GroupMetrics”,“准确性”);di (i + 1) = mmReport.DisparateImpact (2);准确性(i + 1) = mmReport.Accuracy (2);结束图yyaxis左情节(r, di,“线宽”, 1.5)标题(“减轻年龄组别的偏见”)包含(“修复分数”) ylabel (的不同影响) yyaxis正确的情节(r,准确性,“线宽”1.5) ylabel (“准确性”网格)在

如果目标不是衡量每个个体群体对特权群体的偏见,而是衡量不属于特权群体的所有客户的整体公平,那么可以使用这种特权群体和非特权群体方法。
参考文献
[1]尼尔森,艾琳。“第四章。公平预处理。”实际的公平.奥莱利媒体公司,2020年12月。
[2] Mehrabi, Ninareh,等。《机器学习中的偏见和公平性调查》。ArXiv: 1908.09635 (Cs)2019年9月。arXiv.org,https://arxiv.org/abs/1908.09635.
[3] Wachter, Sandra,等。机器学习中的偏见保存:欧盟非歧视法下公平度量的合法性.学术论文,社会科学研究网,ID 3792772, 2021年1月15日。papers.ssrn.com,https://papers.ssrn.com/abstract=3792772。
另请参阅
creditscorecard|autobinning|fitmodel|displaypoints|probdefault
相关的话题
您也可以从以下列表中选择网站: