二类模糊推理系统
对于话语宇宙中的任何值,传统的1型隶属函数只有一个隶属值。因此,虽然type-1隶属函数模拟给定语言集中的隶属度,但它并不模拟隶属度中的不确定性。为了对这种不确定性建模,可以使用区间类型-2成员函数。在这种类型-2隶属度函数中,隶属度可以有一个值范围。
有关使用2型模糊推理系统的例子,请参见2型FIS模糊PID控制而且用2型FIS预测混沌时间序列.
Interval Type-2成员函数
区间类型-2隶属函数由上隶属函数和下隶属函数定义。上层隶属函数(UMF)相当于传统的1型隶属函数。对于所有可能的输入值,下隶属度函数(LMF)小于或等于上隶属度函数。UMF和LMF之间的区域是不确定性的足迹(4)。下图显示了二类三角形隶属函数的UMF(红色)、LMF(蓝色)和FOU(阴影)。
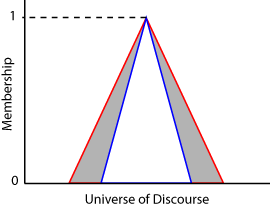
对于语篇宇宙中的每个输入值,隶属度是LMF值和UMF值之间的值的范围。
二类模糊推理系统
使用模糊逻辑工具箱™软件,您可以创建2型Mamdani和Sugeno模糊推理系统。
在2型Mamdani系统中,输入和输出隶属函数都是2型模糊集。
在2型Sugeno系统中,只有输入隶属函数是2型模糊集。输出隶属函数与1型Sugeno系统常数或输入值的线性函数相同。
要在命令行创建2型Mamdani和Sugeno系统,请使用mamfistype2而且sugfistype2对象,分别。这些对象具有与类型-1相同的参数mamfis而且sugfis对象以及附加的TypeReductionMethod参数。
方法创建的现有类型-1系统,例如使用genfis函数。要做到这一点,请使用convertToType2函数。
一旦你创建了二类模糊推理系统,你可以:
方法还可以创建2型模糊推理系统模糊逻辑设计应用程序。
二类模糊系统的模糊推理过程
前期处理
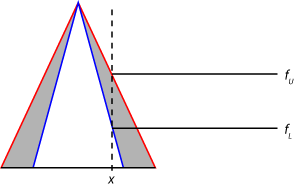
对于2型模糊推理系统,通过从规则先行项中找出umf和lmf中相应的隶属度来模糊输入值。这样做会为每个type-2成员函数生成两个模糊值。例如,下图中的模糊化显示了上层隶属函数中的隶属值(fU)和下隶属函数(fl).
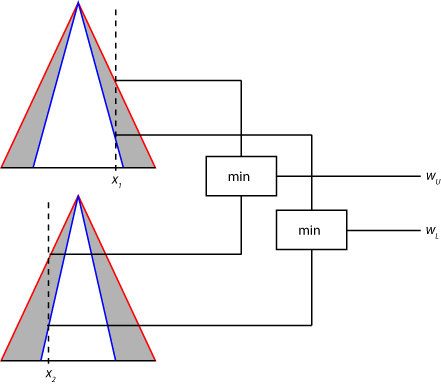
接下来,通过对2型隶属函数的模糊化值应用模糊算符,找到规则触发强度的范围,如下图所示。此范围的最大值(wU)是将模糊算子应用于umf的模糊值的结果。最小值(wl)是将模糊算子应用于来自lmf的模糊值的结果
前因处理在Mamdani和Sugeno系统中是相同的。
后续处理
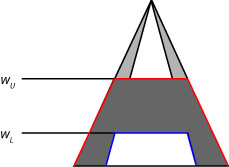
对于Mamdani系统,隐含方法剪辑(最小值含义)或量表(刺激蕴涵)输出类型2隶属函数的UMF和LMF使用规则射击距离限制。这个过程为每个规则生成一个输出模糊集。下图为应用产生的输出模糊集(暗灰色区域)最小值对UMF(红色)和LMF(蓝色)的影响。
对于二类Sugeno系统,输出电平z我为我该规则的计算方法与1型Sugeno系统相同。
在这里,j为输入索引,xj是价值的j输入变量Th,和c项是上层隶属函数的参数
与1型Sugeno系统不同,规则触发强度不用于处理每个规则的结果。相反,在聚合过程中使用输出级别和规则触发强度。
聚合
聚合阶段的目标是从规则输出模糊集中派生出单一的2型模糊集。
对于二类Mamdani系统,该软件通过对所有规则的输出模糊集的umf和lmf进行聚合,找到一个聚合的二类模糊集。下图显示了两种类型-2模糊集(双规则系统的输出)的聚合马克斯聚合。
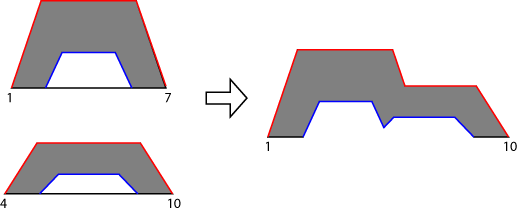
对于二类Sugeno系统,通过以下步骤导出聚合模糊集:
对规则输出级别进行排序(z我)把所有的规则按升序排列。这些输出水平值定义了聚合型2型模糊集的语篇范围。
对于每个输出级别,使用对应规则中的最大射程值定义UMF值。
对于每个输出级别,使用对应规则中的最小射程值定义LMF值。
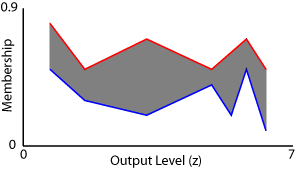
例如,假设您有一个具有7条规则的type-2 Sugeno系统。此外,假设这些规则具有以下输出水平和射程限制。
| 规则 | 输出电平(z) | 最小发射值 | 最大发射值 |
|---|---|---|---|
| 1 | 6.3 | 0.1 | 0.5 |
| 2 | 4.9 | 0.4 | 0.5 |
| 3. | 1.6 | 0.3 | 0.5 |
| 4 | 5.8 | 0.5 | 0.7 |
| 5 | 5.4 | 0.2 | 0.6 |
| 6 | 0.7 | 0.5 | 0.8 |
| 7 | 3.2 | 0.2 | 0.7 |
下图显示了该Sugeno系统的聚合型2模糊集及其相关的UMF(红色)和LMF(蓝色)。
类型缩减和去模糊化
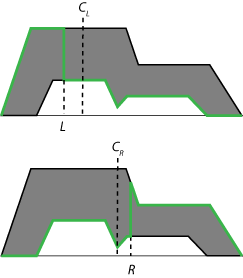
为了找到推理过程的最终清晰输出值,首先将聚合型2型模糊集简化为区间型1型模糊集,这是一个有下限的范围cl和上限cR.这个区间1型模糊集通常被称为2型模糊集的质心。理论上,这个质心是嵌入在第二类模糊集中的所有第一类模糊集的质心的平均值。在实践中,不可能计算出的确切值cl而且cR.相反,使用迭代类型减少方法来估计这些值。
对于给定的聚合型2模糊集,的近似值cl而且cR为下列第1类模糊集(绿色)的质心。
从数学上讲,这些质心可以用下面的公式找到。[1]
在这里:
N在输出变量范围内采样的数量是否指定为
evalfisOptions.x我是我输出值sample。
μumf为上隶属函数。
μlmf为下隶属函数。
l而且R是开关分这是通过各种类型缩减方法估计出来的。有关支持的方法列表,请参见Type-Reduction方法.
对于Mamdani和Sugeno系统,最终去模糊的输出值(y)为类型约简过程中两个质心值的平均值。
Type-Reduction方法
模糊逻辑工具箱软件支持四种内置的类型减少方法。这些算法在初始化方法、假设、计算效率和终止条件上有所不同。
若要设置2型模糊系统的类型简化方法,请设置TypeReduction财产的mamfistype2或sugfistype2对象。
| 方法 | TypeReduction属性值 |
描述 |
|---|---|---|
| Karnik-Mendel(公里)[2] | “karnikmendel” |
第一种减型方法被开发出来 |
| 增强Karnik-Mendel(11月)[3] | “11” |
改进了Karnik-Mendel算法,改进了初始化,改进了终止条件,提高了计算效率 |
| 具有停止条件的迭代算法(IASC)[4] | “关于” |
对蛮力方法的迭代改进 |
| 具有停止条件的改进迭代算法(EIASC)[5] | “eiasc” |
IASC算法的改进版本 |
通常,这些方法的计算效率随着表的下移而提高。
您还可以使用您自己的自定义类型减少方法。有关更多信息,请参见使用自定义函数构建模糊系统.
参考文献
[1]孟德尔,杰瑞·M.,哈尼·哈格拉,谭维万,威廉·w·梅里克,郝英。二类模糊逻辑控制理论与应用导论.霍博肯,新泽西州:IEEE出版社,John Wiley & Sons, 2014。
卡尼克,尼利什·N.和杰瑞·m·孟德尔。第2型模糊集的质心。信息科学132年,没有。1-4(2001年2月):195-220。https://doi.org/10.1016/s0020 - 0255 (01) 00069 - x.
[3]吴,D.和J.M. Mendel,“增强Karnik-Mendel算法,”模糊系统汇刊第17卷,第923-934页。(2009)
[4] Duran, K., H. Bernal,和M. Melgarejo,“计算区间型2模糊集广义质心的改进迭代算法,”北美模糊信息处理学会年会, 190 - 194页。(2008)
[5]吴东、聂明,“二类模糊集和系统的类型约简算法的比较与实践实现”,FUZZ-IEEE学报》,第2131-2138页(2011)
另请参阅
相关的话题
您也可以从以下列表中选择网站: