 克利夫角:克利夫·莫尔谈数学和计算
克利夫角:克利夫·莫尔谈数学和计算 MATLAB的博客
MATLAB的博客 Steve用MATLAB进行图像处理
Steve用MATLAB进行图像处理 人在仿真软件
人在仿真软件 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB社世界杯预选赛小组名单区
MATLAB社世界杯预选赛小组名单区 Matlabユザコミュニティ
Matlabユザコミュニティ 初创公司,加速器和企业家
初创公司,加速器和企业家 自治系统
自治系统
子集选择与正则化(下)
本周,来自技术营销的Richard Willey将完成他关于子集选择和正则化的两部分报告。
在一个最近的帖子,我们研究了在建模具有高度相关变量的广泛数据集时,如何使用顺序特征选择来提高预测精度。本周,我们将使用正则化算法如套索、弹性网和岭回归来解决同样的问题。数学上,这些算法通过惩罚模型中回归系数的大小来工作。
标准线性回归通过估计一组系数来最小化观测值和模型拟合值之间的平方误差之和。像脊回归、套索和弹性网这样的正则化技术为这个最小化问题引入了一个额外的术语。
- 岭回归确定了一组回归系数,使误差平方和加上回归系数平方和乘以权重参数最小
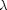 .可以取0到1之间的任何值。一个0的值等价于标准线性回归。作为随着规模的增加,回归系数会缩小到零。
.可以取0到1之间的任何值。一个0的值等价于标准线性回归。作为随着规模的增加,回归系数会缩小到零。 - 拉索使误差平方和加上回归系数绝对值的和最小化。
- 弹性网是套索解和脊解的加权平均值。
引入这一附加项使回归系数趋近于零,从而产生一个更简单的模型,具有更高的预测精度。
让我们来看看如何使用lasso来解决我们上周讨论的相同问题。
内容
从上一篇文章重新创建数据集1
清晰的所有clc rng (1998);Mu = [0 0 0 0 0 0 0 0 0];我= 1:8;矩阵= abs (bsxfun (@minus,我,我));协方差= repmat(5 8 8)。^矩阵;X = mvnrnd(mu,协方差,20);β= [3;1.5;0;0; 2; 0; 0; 0]; ds = dataset(Beta); Y = X * Beta + 3 * randn(20,1); b = regress(Y,X); ds.Linear = b;
使用套索来贴合模型
的语法套索命令与线性回归使用的命令非常相似。在这行代码中,我要估计一组系数B这个模型Y作为X.为了避免过度拟合,我将应用五倍交叉验证。
[B Stats] =套索(X,Y,“简历”5);
当我们执行线性回归时,我们生成一组回归系数。默认情况下套索将创造100种不同的模型。每个模型都使用略大的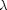 .所有的模型系数都存储在数组中B.关于模型的其余信息存储在一个名为统计数据.
.所有的模型系数都存储在数组中B.关于模型的其余信息存储在一个名为统计数据.
让我们看看里面的前五组系数B.当你遍历这些行时,你可以看到增加时,值模型系数通常收缩为零。
disp (B (: 1:5) disp(统计)
3.9147 3.9146 3.9145 3.9143 3.9142 0.13502 0.13498 0.13494 0.13488 0.13482 0.85283 0.85273 0.13494 0.13488 0.13482 0.85283 0.85273 0.85273 0.85262 0.85247 0.85232 -0.92775 -0.92723 -0.9267 -0.92525 3.9415 3.9409 3.9404 3.9397 3.9389 -2.2945 -2.294 -2.2936 -2.293 -2.2924 1.3566 1.3567 1.3568 1.3568 1.3569 1.3571 -0.14796 -0.14803 -0.1481 -0.14821 -0.14833 Intercept: [1x100双]Lambda: [1x100双]Alpha: 1 DF: [1x100双]MSE: [1x100双]PredictorNames: {} SE: [1x100双]LambdaMinMSE: 0.585 Lambda1SE: 1.6278 IndexMinMSE:78 Index1SE: 89
创建一个显示均方误差与Lambda的图表
此时,人们自然会问:“好吧,我应该使用这100个不同的模型中的哪一个?”我们可以用lassoPlot.lassoPlot生成一个显示之间关系的图以及所得模型的交叉验证均方误差(MSE)。每个红点表示结果模型的均方误差。从每个点延伸出的垂直线段是每个估计的误差条。
您还可以看到一对垂直虚线。右边的线表示使交叉验证MSE最小的值。左边的线表示的最大值其均方误差在最小均方误差的一个标准误差范围内。一般来说,人们会选择最小化MSE。有时,如果一个更节俭的模型被认为特别有利,用户可能会选择其他的位于两条线段之间的值。
lassoPlot (B,统计数据,“PlotType”,“简历”)

使用统计结构提取一组模型系数。
的使MSE最小的值存储在统计数据结构。您可以使用此信息进行索引β并提取最小均方误差的系数集。
就像在特征选择的例子中一样,我们可以看到lasso算法从结果模型中消除了五个干扰中的四个。这个新的,更简洁的模型将明显比标准线性回归预测更准确。
ds。套索= B (:, Stats.IndexMinMSE);disp (ds)
Beta线性套索3 3.5819 3.0591 1.5 0.44611 0.3811 0 0.92272 0.024131 0 -0.84134 02 4.7091 1.5654 0 -2.5195 0 0 0.17123 1.3499 0 -0.42067 0
运行一个仿真
在这里,再次强调,将任何分析建立在单一的观察结果之上都是非常危险的。让我们用一个模拟来比较线性回归和套索的准确性。我们先从预分配变量开始。
MSE = 0 (100 1);mse = 0 (100 1);Coeff_Num = 0 (100 1);贝塔= 0 (8100);cv_Reg_MSE = 0 (1100);
接下来,我们将生成100个不同的模型,并估计套索模型中包含的系数数量,以及标准线性回归和套索模型之间的交叉验证MSE的差异。
可以看到,lasso模型平均只包含4.5项(标准线性回归模型包含8项)。更重要的是,线性回归模型的交叉验证MSE比由套索.这是一个非常强大的结果。的套索算法和标准线性回归一样易于应用,但是,与回归相比,它在预测精度方面提供了显著的改进。
rng (1998);为i = 1: 100 X = mvnrnd(mu,协方差,20);Y = X * Beta + randn(20,1);[B Stats] =套索(X,Y,“简历”5);Betas(:,i) = B(:,Stats.IndexMinMSE) > 0;Coeff_Num(i) = sum(B(:,Stats.IndexMinMSE) > 0);MSE (i) =统计数据。MSE (:, Stats.IndexMinMSE);regf = @(XTRAIN, ytrain, XTEST)(XTEST* return (ytrain,XTRAIN));cv_Reg_MSE (i) = crossval (mse的, X, Y,“predfun”regf,“kfold”5);结束Number_Lasso_Coefficients =意味着(Coeff_Num);disp(Number_Lasso_Coefficients) MSE_Ratio = median(cv_Reg_MSE)/median(MSE);disp (MSE_Ratio)
4.57 - 1.2831
选择最好的技术
正则化方法和特征选择技术都有各自独特的优缺点。让我们以一些关于各种技术优缺点的实际指导来结束这篇博客文章。
与特征选择相比,正则化技术有两个主要优势。
- 正则化技术比特征选择方法能够操作更大的数据集。套索和岭回归可以应用于包含数千甚至数万个变量的数据集。即使是连续的特征选择通常也太慢,无法处理这么多可能的预测因素。
- 正则化算法通常生成比特征选择更精确的预测模型。正则化作用于连续空间,而特征选择作用于离散空间。因此,正则化通常能够微调模型并产生更准确的估计。
然而,特征选择方法也有其优点
- 正则化技巧只适用于少数模型类型。值得注意的是,正则化可以应用于线性回归和逻辑回归。然而,如果您正在使用其他建模技术——比如增强的决策树——您通常需要应用特征选择技术。
- 特性选择更容易向第三方理解和解释。永远不要低估在分享你的成果时能够描述你的方法的重要性。
说了这些,做了这些,三种正则化技术中的每一种都提供了自己独特的优点和缺点。
- 因为套索使用L1范数,它倾向于迫使个别系数值完全趋近于零。因此,lasso作为一种特征选择算法非常有效。它可以快速识别出少量的关键变量。
- 相反,岭回归对系数使用L2范数(使误差平方和最小化)。岭回归倾向于将系数收缩扩散到更多的系数上。如果你认为你的模型应该包含大量的系数,岭回归可能是一个比套索更好的选择。
- 最后,但并非最不重要的是,我们有弹性网,它能够补偿套索的一个非常具体的限制。拉索无法识别比系数更多的预测因子。
假设你正在进行一项癌症研究。
- 你有500个不同癌症患者的基因序列
- 你要确定15000个不同的基因中哪一个对疾病的发展有重大影响。
对于这么多不同的变量,顺序特征选择是完全不切实际的。你不能使用岭回归,因为它不会迫使系数足够快地完全归零。与此同时,你不能使用套索,因为你可能需要识别500多个不同的基因。弹性网是一个可能的解决方案。
结论
如果您想了解关于这个主题的更多信息,可以在MathWork的一个名为“计算统计:特征选择、正则化和收缩”的网络研讨会上查看,该研讨会对这些主题提供了更详细的处理。
最后,我想问你们是否有人在你们的工作中有应用特征选择或正则化算法的实际例子?
- 你用过特征选择吗?
- 你是否看到了在你的工作中应用套索或脊回归的机会?
如果有,请在这里发帖在这里.





