在机器学习中,从开始到结束很少有一条直线——你会发现自己在尝试不同的想法和方法。
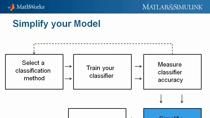
今天,我们将一步一步地介绍机器学习的工作流程,并将关注过程中的几个关键决策点。
每个机器学习工作流都从三个问题开始:
- 您正在处理哪类数据?
- 你想从中得到什么见解?
- 如何以及在哪里应用这些见解?
本视频中的例子是基于一个手机健康监测应用程序。输入由来自手机加速计和陀螺仪的传感器数据组成。
反应就是所进行的活动——步行、站立、跑步、爬楼梯或躺下。我们希望利用传感器数据训练分类模型来识别这些活动。
现在让我们逐步了解工作流程的每个部分,看看如何让我们的健身应用程序工作。
我们从手机传感器的数据开始。
文本或CSV等平面文件格式很容易使用,可以直接导入数据。
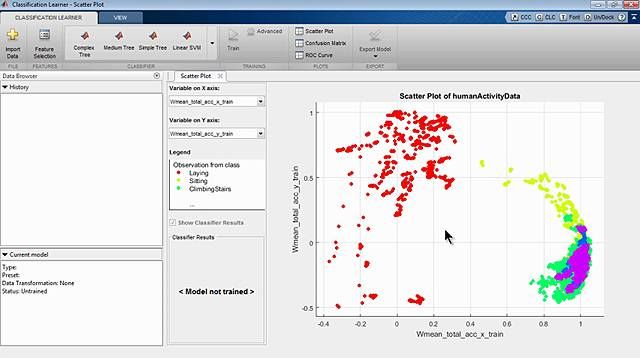
现在我们将所有的数据导入到MATLAB中,并绘制每个标记集,以了解数据中的内容。
为了对数据进行预处理,我们寻找丢失的数据或异常值。在这种情况下,我们也可以考虑使用信号处理技术来消除低频引力效应。这将有助于算法关注被摄物的运动,而不是手机的方向。
最后,我们将数据分为两组。我们保存一部分数据用于测试,并使用其余的数据来构建模型。
特征工程是机器学习中最重要的部分之一。它将原始数据转化为机器学习算法可以使用的信息。
对于活动跟踪器,我们希望提取捕获加速计数据频率内容的特征。
这些特征将帮助算法区分行走(低频)和奔跑(高频)。
我们创建一个包含所选特性的新表。
你能推导出的特征的数量只受限于你的想象力。但是,对于不同类型的数据,通常使用许多技术。
现在是时候构建和训练模型了。
从像基本决策树这样简单的东西开始是个好主意。这将运行得很快,很容易解释。
要了解它的性能如何,我们查看混淆矩阵,这是一个比较模型所做分类与实际类标签的表。
混淆矩阵表明我们的模型在区分跳舞和跑步方面有困难。
也许决策树并不适合这类数据。我们试试别的。
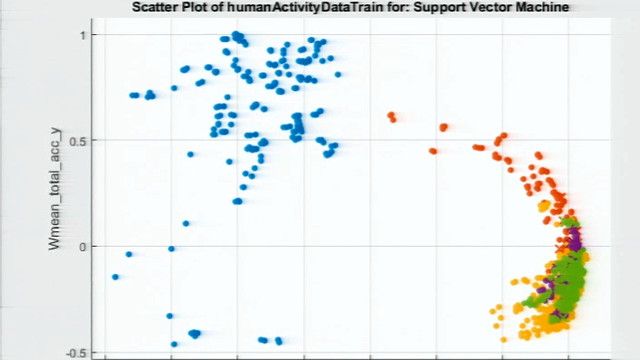
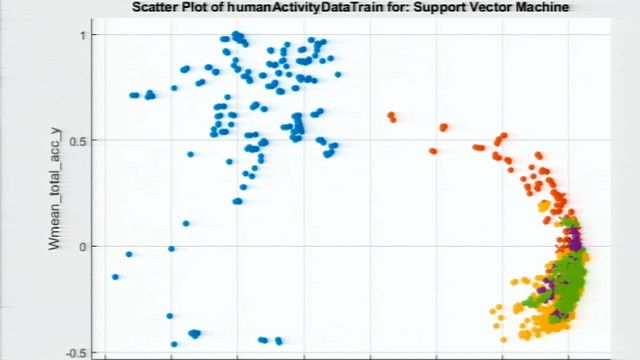
让我们试试多类支持向量机(SVM)。
使用这种方法,我们现在获得了99%的准确率,这是一个很大的改进。
我们通过迭代模型和尝试不同的算法来实现我们的目标,但是很少有这么简单的。
如果我们的分类器仍然不能可靠地区分跳舞和跑步,我们就会寻找其他方法来改进模型。
改进一个模型可以采取两个不同的方向:使模型更简单以避免过度拟合,或增加复杂性以提高精度。
一个好的模型只包含最有预测能力的特征,所以为了简化模型,我们首先应该尝试减少特征的数量。
有时,我们会寻找减少模型本身的方法。我们可以通过修剪决策树的分支或从集合中删除学习者来实现这一点
如果我们的模型仍然不能区分跑步和跳舞,这可能是由于过度一般化。因此,为了微调我们的模型,我们可以添加额外的特征。
在我们的例子中,陀螺仪记录了手机在活动过程中的方向。
此数据可能为不同的活动提供惟一的签名。
例如,可能有一种奔跑特有的加速和旋转的组合。
现在我们已经调整了我们的模型,我们可以根据我们在预处理中保留的测试数据来验证它的性能。如果模型能够可靠地对活动进行分类,我们就可以将其转移到手机上并开始跟踪。
好了,我们的机器学习例子和关于机器学习的总览系列视频就讲到这里。欲了解更多信息,请查看下面的链接。
在下一个系列中,我们将讨论一些与机器学习相关的高级主题,比如特征工程和超参数调优。