什么是目标检测?
你需要知道3件事
目标检测是先进驾驶辅助系统(ADAS)背后的关键技术,该系统使汽车能够检测行车车道或执行行人检测,以提高道路安全。物体检测在视频监控或图像检索系统等应用中也很有用。

使用物体检测来识别和定位车辆。
使用深度学习的目标检测
您可以使用各种技术来执行对象检测。基于深度学习的流行方法卷积神经网络(cnn),如R-CNN和YOLO v2,自动学习检测图像中的物体。
你可以从两种关键方法中选择,开始使用深度学习进行目标检测:
- 创建并训练一个自定义对象检测器。为了从头开始训练自定义对象检测器,您需要设计一个网络体系结构来学习感兴趣的对象的特性。你还需要编译一个非常大的标记数据集来训练CNN。自定义对象检测器的结果可能是显著的。也就是说,你需要手动设置CNN中的层和权重,这需要大量的时间和训练数据。
- 使用预先训练好的目标检测器。许多使用深度学习的对象检测工作流程都有杠杆作用转移学习,这种方法使您能够从预先训练好的网络开始,然后根据应用程序对其进行微调。这种方法可以提供更快的结果,因为物体探测器已经在数千甚至数百万张图像上进行了训练。

使用预先训练好的R-CNN检测停车标志。看例子.
无论您是创建自定义对象检测器还是使用预训练的对象检测器,您都需要决定您想要使用的对象检测网络类型:两级网络还是单级网络。
两级网络
两级网络的初始阶段,如R-CNN及其变体,确定地区的建议,或可能包含对象的图像子集。第二阶段对区域建议内的对象进行分类。两级网络可以实现非常精确的目标检测结果;然而,它们通常比单级网络慢。
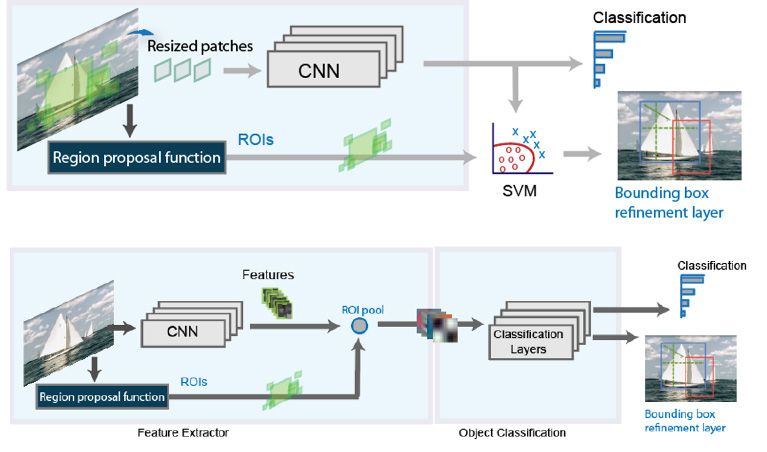
R-CNN(上)和快速R-CNN(下)目标检测的高级架构。
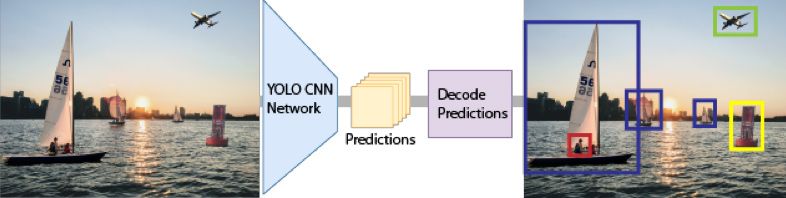
YOLO v2对象检测概述。
使用机器学习的目标检测
机器学习技术也常用于目标检测,它们提供了与深度学习不同的方法。常见的机器学习技术包括:
- 聚合信道特征(ACF)
- 基于HOG特征直方图的支持向量机分类
- 用于人脸或上半身检测的维奥拉-琼斯算法
使用ACF对象检测算法跟踪行人。看例子.
类似于基于深度学习的方法,您可以选择从预训练的对象检测器开始,也可以创建适合您应用程序的自定义对象检测器。与基于深度学习的工作流中的自动特征选择相比,在使用机器学习时,您将需要手动选择对象的识别特征。
机器学习与深度学习的目标检测
确定对象检测的最佳方法取决于您的应用程序和您试图解决的问题。在机器学习和深度学习之间进行选择时,要记住的主要考虑因素是你是否拥有强大的GPU和大量标记的训练图像。如果其中一个问题的答案是否定的,那么机器学习方法可能是更好的选择。当你有更多的图像时,深度学习技术往往工作得更好,gpu减少了训练模型所需的时间。

基于点特征匹配的混沌场景目标检测。看例子.
只用了几行MATLAB®代码,你可以为目标检测构建机器学习和深度学习模型,而不必成为专家。
自动标签训练图像与应用程序
MATLAB提供了交互式应用程序来准备训练数据和定制卷积神经网络。为目标检测器的测试图像标记是乏味的,并且需要花费大量的时间来获得足够的训练数据来创建一个高性能的目标检测器。的图像标签应用程序允许您在图像集合中交互式地标记对象,并提供内置算法来自动标记您的真实数据。对于自动驾驶应用程序,您可以使用Ground Truth Labeler应用,对于视频处理工作流,可以使用视频标签应用程序.
交互式创建对象检测算法和框架之间的互操作
定制现有的CNN或从头创建CNN容易出现架构问题,从而浪费宝贵的培训时间。的深度网络设计器应用程序使您能够交互式地构建、编辑和可视化深度学习网络,同时还提供了一个分析工具,在训练网络之前检查架构问题。
使用MATLAB,您可以使用ONNX™(Open Neural network Exchange)导入和导出功能与来自TensorFlow™-Keras、PyTorch和Caffe2等框架的网络和网络架构进行互操作。

从ONNX导入和导出。看例子.
自动生成用于部署的优化代码
在用MATLAB创建算法之后,您可以利用自动化工作流来生成TensorRT或CUDA®代码与GPU编码器™执行硬件在环测试。生成的代码可以与现有项目集成,并可用于验证桌面gpu或嵌入式gpu(如NVIDIA)上的对象检测算法®Jetson或NVIDIA Drive平台。








30天免费试用

问题吗?
您也可以从以下列表中选择一个网站: