基于分类学习者App的特征选择与特征转换
研究散点图中的特征
在分类学习者中,尝试通过在散点图上绘制不同的预测对来识别能够很好地区分类的预测因子。图可以帮助你调查包括或排除的特征。你可以在散点图上可视化训练数据和错误分类的点。
在训练分类器之前,散点图会显示数据。如果训练了分类器,则散点图显示模型预测结果。通过选择切换到只绘制数据数据在情节控制。
选择要绘制的特征X而且Y列表下预测.
寻找能够很好地区分类别的预测器。例如,绘制
fisheriris数据,你可以看到萼片的长度和萼片的宽度分开一个类很好(setosa).您需要绘制其他预测器,以查看是否可以分离其他两个类。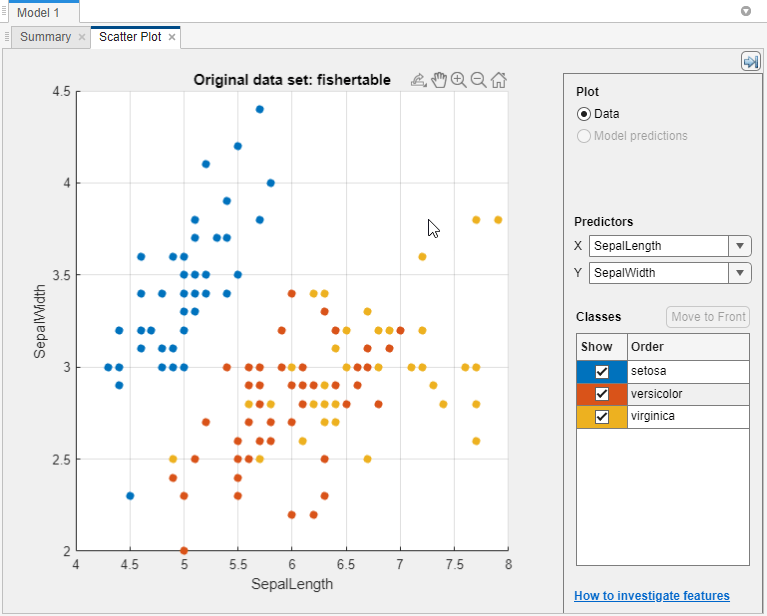
使用下面的复选框显示或隐藏特定的类显示.
通过选择下面的一个类来更改所绘制类的堆叠顺序类然后点击移到前面.
通过放大缩小和在整个情节中平移来研究更精细的细节。要启用缩放或平移,请将鼠标悬停在散点图上,并单击出现在图右上方的工具栏上的相应按钮。
如果您确定的预测符对分离类没有帮助,那么请尝试使用特征选择删除它们并训练分类器,只包括最有用的预测器。看到选择要包含的功能.

训练分类器后,散点图显示模型预测结果。您可以显示或隐藏正确或不正确的结果,并按类可视化结果。看到情节分类器的结果.
你可以将你在应用程序中创建的散点图导出为数字。看到在分类学习者应用程序中导出情节.
选择要包含的功能
在Classification Learner中,可以指定要包含在模型中的不同特征(或预测器)。看看是否可以通过删除预测能力较低的特征来改进模型。如果数据收集是昂贵的或困难的,您可能喜欢一个不需要一些预测器就能令人满意地执行的模型。
您可以通过使用不同的特征排序算法来确定要包含哪些重要的预测器。在你选择一个特征排序算法后,应用程序会显示一个排序后的特征重要性分数的图表,其中较大的分数(包括正S)表示更大的特征重要性。该应用程序还会在表格中显示排名功能及其得分。
在“分类学习器”中使用特征排序算法,请单击特征选择在选项部分的分类学习者选项卡。该应用程序打开一个默认的特征选择选项卡,在这里您可以选择一个特征排序算法。
| 排名算法特点 | 支持的数据类型 | 描述 |
|---|---|---|
| MRMR | 分类和连续的特征 | 对功能进行排序最小冗余最大相关性(MRMR)算法. 有关更多信息,请参见 |
| Chi2 | 分类和连续的特征 | 通过使用单个卡方检验检查每个预测变量是否独立于响应变量,然后使用p-卡方检验统计值。分数对应日志(p). 有关更多信息,请参见 |
| ReliefF | 要么全部绝对特征,要么全部连续特征 | 使用ReliefF算法。该算法最适合于估计基于距离的监督模型的特征重要性,该模型使用观测之间的成对距离来预测响应。 有关更多信息,请参见 |
| 方差分析 | 分类和连续的特征 | 对每个预测变量进行单因素方差分析,按类分组,然后使用p值。对于每一个预测变量,应用程序会测试一个假设,即根据响应类别分组的预测值来自具有相同均值的总体,而另一个假设是,总体均值并不都相同。分数对应日志(p). 有关更多信息,请参见 |
| Kruskal沃利斯 | 分类和连续的特征 | 使用p函数返回的值克鲁斯卡尔-沃利斯检验.对于每一个预测变量,应用程序会测试一个假设,即根据响应类别分组的预测值来自具有相同中位数的人群,另一个假设是,人群中位数并不都相同。分数对应日志(p). 有关更多信息,请参见 |
在选择排名最高的功能和选择单个功能之间进行选择。
选择选择排名最高的功能避免验证指标的偏差。例如,如果您使用交叉验证方案,那么对于每个训练折叠,应用程序在训练模型之前执行特征选择。不同的折叠可以选择不同的预测因子作为排名最高的特征。
选择选择个人特性在模型训练中包含特定的特征。如果你使用交叉验证方案,那么应用程序在所有训练折叠中使用相同的功能。
完成选择特性后,单击保存和应用.您的选择将影响所有草稿模型模型窗格中的图库创建的新草稿模型模型部分的分类学习者选项卡。
要为单个草稿模型选择功能,打开并编辑模型摘要。中单击模型模型窗格,然后单击模型总结选项卡(如果有必要)。的总结TAB包含一个可编辑项特征选择部分。
在你训练一个模型之后特征选择模型截面总结TAB列出了用于训练完整模型(即使用训练和验证数据训练的模型)的特性。要了解更多关于分类学习者如何将特征选择应用于数据的信息,请为训练过的分类器生成代码。有关更多信息,请参见生成MATLAB代码,用新数据训练模型.
有关使用特性选择的示例,请参见使用分类学习应用程序训练决策树.
分类学习器中的PCA特征变换
利用主成分分析(PCA)来降低预测空间的维数。在分类学习者中,降低维数可以创建分类模型,防止过拟合。PCA对预测因子进行线性变换以去除冗余维度,并生成一组称为主成分的新变量。
在分类学习者选项卡,选项部分中,选择主成分分析.
在“默认PCA选项”对话框中,选择使主成分分析复选框,然后单击保存和应用.
应用程序将更改应用到所有现有的草案模型模型窗格中使用图库创建的新草稿模型模型部分的分类学习者选项卡。
当你下次训练一个模型使用火车都按钮时,
主成分分析函数在训练分类器之前转换所选的特征。默认情况下,PCA只保留解释95%方差的成分。在默认PCA选项对话框中,您可以通过选择解释的方差价值。较高的值有过拟合的风险,而较低的值有删除有用维度的风险。
如果您想手动限制PCA组件的数量,请选择
指定组件数量在组件降低标准列表。选择数值分量数价值。组件的数量不能大于数值预测器的数量。主成分分析不适用于分类预测器。
中的经过训练的模型的PCA选项主成分分析部分的总结选项卡。中单击经过训练的模型模型窗格,然后单击模型总结选项卡(如果有必要)。例如:
PCA保留了足够的分量来解释95%的方差。训练结束后,保留2个组分。每个成分的解释方差(按顺序):92.5%,5.3%,1.7%,0.5%
要了解更多关于分类学习者如何将PCA应用到您的数据,请为训练过的分类器生成代码。有关PCA的更多信息,请参见主成分分析函数。
平行坐标图的特征研究
要研究包括或排除的特征,使用平行坐标图。您可以在单个图上可视化高维数据,以查看2-D模式。图可以帮助您理解特征之间的关系,并识别用于分离类的有用预测器。你可以在平行坐标图上可视化训练数据和分类错误的点。在绘制分类器结果时,分类错误的点有虚线。
在分类学习者选项卡,情节和解释部分,单击箭头打开图库,然后单击平行坐标在验证结果组。
在图上,拖动X在标签上打勾以重新排列预测器。改变顺序可以帮助您识别能够很好地分离类的预测器。
方法指定要绘制的预测器预测复选框。一个好的实践是一次绘制几个预测器。如果您的数据有许多预测器,则图默认显示前10个预测器。
如果预测因子具有显著不同的尺度,请缩放数据以更容易可视化。尝试不同的选项扩展列表:
没有一个沿着具有相同最小和最大限制的坐标标尺显示原始数据。范围沿着具有独立最小和最大限制的坐标标尺显示原始数据。z分数显示每个坐标标尺上的z值(平均值为0,标准差为1)。零均值显示以中心为中心的数据,使每个坐标标尺的平均值为0。单位方差显示沿每个坐标标尺按标准偏差缩放的值。L2范数沿着每个坐标标尺显示2范数。
如果您确定的预测符对分离类没有帮助,请使用特征选择删除它们并训练分类器,只包括最有用的预测器。看到选择要包含的功能.
的情节fisheriris数据显示,花瓣长度和花瓣宽度特征是区分类的最佳特征。

有关更多信息,请参见parallelplot.
你可以导出你在应用程序中创建的平行坐标图。看到在分类学习者应用程序中导出情节.
相关的话题
您也可以从以下列表中选择网站: