clusterDBSCAN
基于密度的数据聚类算法
描述
clusterDBSCAN集合属于的数据点P-维特征空间利用基于密度的空间聚类应用带噪声(DBSCAN)算法。聚类算法将特征空间中彼此接近的点分配到单个聚类中。例如,雷达系统可以返回在距离、角度和多普勒上紧密间隔的扩展目标的多次探测。clusterDBSCAN将这些检测分配给单个检测。
DBSCAN算法假设集群是数据空间中的密集区域,由密度较低的区域分隔,并且所有的密集区域密度相似。
为了测量一个点的密度,算法计算该点附近的数据点的数量。社区是一个P特征空间中的-维椭圆(超椭圆)。椭圆的半径由函数定义P向量ε。ε可以是一个标量,在这种情况下,超椭圆就变成了超球。特征空间中点之间的距离使用欧氏距离度量计算。这个邻域叫做ε-邻域。ε的值由
ε财产。ε可以是标量或P向量:当特征空间的不同维度具有不同的单位时,就使用向量。
标量对所有维度应用相同的值。
聚类从找到所有开始核心点。如果一个点在它的ε-邻域内有足够多的点,这个点被称为核心点。一个点成为核心点所需的最小点数由
MinNumPoints财产。核心点的ε-邻域的其余点可以是核心点本身。如果不是,它们就是边境点。ε-邻域中的所有点都叫做直接密度可及从核心观点出发。
如果一个核心点的ε-邻域包含其他核心点,则所有核心点的ε-邻域中的点合并在一起,形成ε-邻域的并集。这个过程将持续下去,直到不再添加核心点为止。
ε-邻域并集中的所有点都是密度可及从第一个核心点开始。事实上,从联盟的所有核心点,联盟的所有点都是密度可达的。
ε-邻域并集中的所有点也被命名密度连接尽管边界点不一定可获得的从对方。一个集群是密度连接点的最大集合,可以具有任意形状。
不是核心点或边界点的点是噪音点。它们不属于任何集群。
的
clusterDBSCAN对象可以用a估计εk-最近邻搜索,或者您可以指定值。要让对象估计ε,设EpsilonSource财产“汽车”.的
clusterDBSCAN对象可以消除包含歧义的数据。距离和多普勒可能是模棱两可的数据的例子。集EnableDisambiguation财产真正的消除歧义的数据。
集群检测:
创建
clusterDBSCAN对象并设置其属性。调用带有参数的对象,就像调用函数一样。
要了解更多关于System对象如何工作的信息,请参见什么是系统对象?
创建
描述
clusterer运算= clusterDBSCANclusterDBSCAN对象,clusterer运算,具有默认属性值的对象。
clusterer运算= clusterDBSCAN(名称,值)clusterDBSCAN对象,clusterer运算,使用每个指定的属性的名字设置为指定的价值.可以以任意顺序指定附加的名称-值对参数,如(Name1,Value1、……以,家).任何未指定的属性都采用默认值。例如,
clusterer运算= clusterDBSCAN (“MinNumPoints”3,‘ε’,2,...“EnableDisambiguation”,真的,“AmbiguousDimension”[1, 2]);
EnableDisambiguation属性设置为true和AmbiguousDimension设置为[1,2].
属性
使用
语法
描述
[也返回一组备用的集群id,idx,clusterids] = clusterer运算(X)clusterids,用于分阶段。RangeEstimator而且分阶段。DopplerEstimator对象。clusterids为每个噪声点分配一个唯一的ID。
输入参数
输出参数
对象的功能
要使用对象函数,请将System对象™指定为第一个输入参数。例如,释放名为obj,使用以下语法:
发行版(obj)
例子
距离和多普勒的聚类检测
创建探测范围和多普勒测量的扩展对象。假设最大无歧义距离为20 m,无歧义多普勒跨度从
赫兹,
赫兹。此示例的数据包含在dataClusterDBSCAN.mat文件。数据矩阵的第一列表示距离,第二列表示多普勒。
输入的数据中包含扩展目标和虚告警:
一个明确的目标,位于
一个多普勒定位的模糊目标
在射程内的一个模糊的目标
一个在距离和多普勒上有歧义的目标
5假警报
创建一个clusterDBSCAN对象,并通过设置指定不执行消歧EnableDisambiguation来假.求解聚类指标。
负载(“dataClusterDBSCAN.mat”);cluster1 = clusterDBSCAN (“MinNumPoints”3,‘ε’,2,...“EnableDisambiguation”、假);idx = cluster1 (x);
使用clusterDBSCAN情节对象函数来显示集群。
情节(cluster1, x, idx)

图中显示有8个明显的聚类和6个噪声点。“尺寸1 'Label对应于range和'维度2》标签对应多普勒。
接下来,创建另一个clusterDBSCAN对象并设置EnableDisambiguation来真正的指定跨范围和多普勒模糊边界进行聚类。
cluster2 = clusterDBSCAN (“MinNumPoints”3,‘ε’,2,...“EnableDisambiguation”,真的,“AmbiguousDimension”[1, 2]);
使用歧义限制执行聚类,然后绘制聚类结果。DBSCAN聚类结果正确显示了4个聚类和5个噪声点。例如,距离接近零的点与距离接近20米的点聚在一起,因为最大的明确范围是20米。
amblims = [0 maxRange;minDoppler maxDoppler];idx = cluster2 (x, amblims);情节(cluster2 x, idx)

Epsilon对聚类的影响
利用聚类二维笛卡尔位置数据clusterDBSCAN.为了说明epsilon的选择如何影响聚类,将聚类结果与ε设置为1ε设置为3。
创建随机目标位置数据xy笛卡儿坐标。
2 x =[兰德(20日)+ 12;兰特(20,2)+ 10;兰德(20,2)+ 15);情节(x (: 1) x (:, 2),“。”)

创建一个clusterDBSCAN对象的ε属性设置为1和MinNumPoints属性设置为3。
clusterer运算= clusterDBSCAN (‘ε’, 1“MinNumPoints”3);
当需要群集数据时ε等于1。
idxEpsilon1 clusterer运算(x) =;
再次将数据聚类ε设置为3。的值可以更改ε因为它是一个可调属性。
clusterer运算。ε=3.; idxEpsilon2 = clusterer(x);
并排绘制聚类结果。通过传递轴句柄和标题到情节方法。剧情显示ε设置为1时,将出现三个集群。当ε为3时,两个较低的集群合并为一个。
hAx1 =情节(1、2、1);情节(clusterer运算,x, idxEpsilon1...“父”hAx1,“标题”,“ε= 1”) hAx2 = subplot(1,2,2);情节(clusterer运算,x, idxEpsilon2...“父”hAx2,“标题”,“ε= 3”)

算法
聚类算法
本节说明集群形成的基本原理。图中显示了二维特征空间中的点。这些簇紧密且分离良好。出现了一些噪声点。

集群从核心点开始。算法的第一步是识别所有核心点。
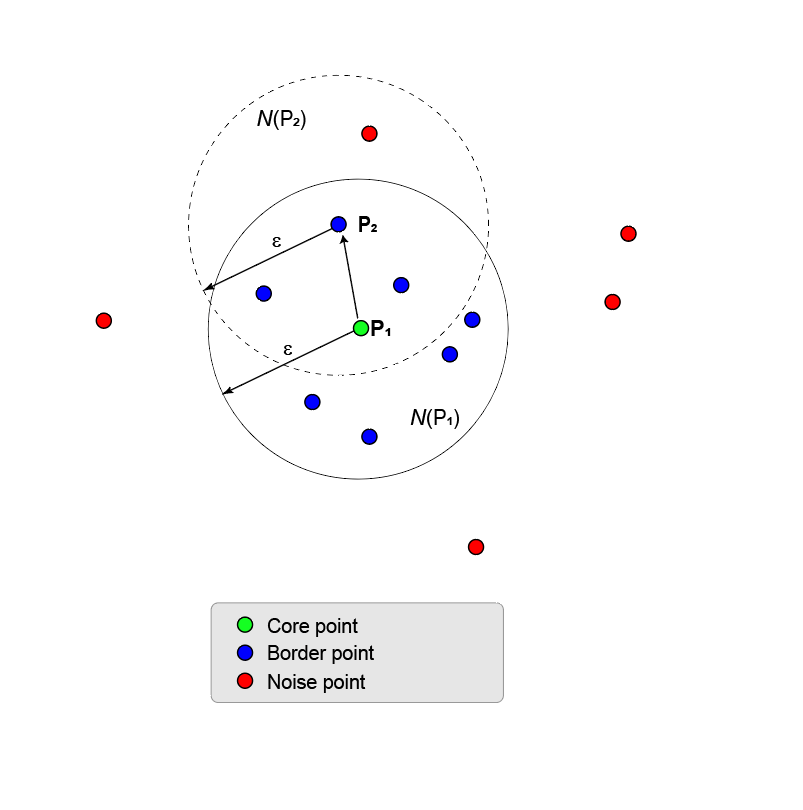
这张图显示了这一点P1和它的ε附近Nε(P1).ε邻域在ε半径内有8个点(包括它自己)。使用
MinNumPoints属性将阈值设置为8意味着P1是一个核心点。蓝色的点在里面Nε被称为边界点.这些边界点是直接密度可及从核心观点来看P1.图中没有其他点的ε-邻域中有足够的相邻点成为核心点。P2不是一个核心点,因为它的周边只有5个点。P2密度是否可以直接到达P1.反之则不然,因为P2不是一个核心点。连接这两点的单向箭头显示了这种不对称性。
落在外面的点Nε(P1)噪音点(红色)和不属于集群。
由于没有其他点是核心点,核心点和边界点是密度连接点的最大集合,因此形成一个聚类。
下图显示了一个更大的点集,其中包含两个核心点,P1而且P2.P2边界点是多少P1但P2也有足够的点在自己的社区成为一个核心点。因为它们都是核心点,P1密度是否可以直接到达P2,P1密度是否可以直接到达P2.连接它们的双向箭头显示了这种对称性。
P3.密度是否可以直接到达P2但不从P1(由单向箭头指示)。然而,P3.被称为简单密度可及从P1.
由于没有其他点为核心点,因此两个核心点及其边界点构成密度连接点的最大集合,形成一个聚类。


集群的成长过程可以从一个核心点扩展到另一个核心点,直到没有更多的核心点可以添加,核心点和边界点属于同一个集群。一般来说,一点Pn从这个点可以到达密度吗P1当有一个核心点链时,P1,P2,P3.、……Pn - 1这样每一个核心点P我+1密度是否可以直接到达P我,Pn密度是否可以直接到达Pn-1.

下一个图说明了密度连通性的一些属性。
一个集群可以有多个分支链,例如(P1,P2,P3.,P4)和(P1,P2,P5,P6).
两个点,P6而且P4,都是密度连接当有第三点的时候P2这样P6而且P4密度是否可以从P2.
两个密度连接点彼此之间并不一定密度可达。
由密度最大的连接点集合定义一个簇。哪个中心点是起始中心点并不重要。
集群中的所有点都可以从所有核心点到达。

估计ε
DBSCAN聚类需要一个邻域大小参数ε的值。的clusterDBSCAN对象和clusterDBSCAN.estimateEpsilon函数使用一个k-最近邻搜索来估计一个标量。让D是任何一点的距离P对其kth最近的邻居。定义一个Dk(P)-邻里作为邻里周围P包含它的k最近的邻居。有k+ 1分Dk(P)——包括点在内的邻居P本身。估计算法的概要如下:
对于每一个点,求出它的所有点Dk(P)附近
累计所有的距离Dk(P)-所有点的邻域到一个单一的向量。
通过增加距离对向量排序。
情节的排序k-dist图,它是对点数排序的距离。
找到曲线的膝盖。这个点的距离值是的估计值。
这里的图显示了距离与点索引的关系k= 20。膝盖大约在1.5处。低于此阈值的任何点都属于集群。任何高于这个值的点都是噪声。

有几种方法可以找到曲线的膝。clusterDBSCAN而且clusterDBSCAN.estimateEpsilon首先定义连接曲线的第一个点和最后一个点的直线。点在被排序矩阵上的纵坐标k距离直线最远且垂直于直线的-dist图定义为。

的范围时k值,算法对所有曲线的估计值取平均值。这个图表明,对不敏感k为k从14岁到19岁。

要创建单个k-NN距离图,设置MinNumPoints属性等于MaxNumPoints财产。
参考文献
[1] Ester M., Kriegel h . p .;, Sander J., Xu X.。“一种基于密度的大型噪声空间数据库聚类发现算法”。Proc。第二Int。知识发现与数据挖掘研讨会,波特兰,OR, AAAI出版社,1996,页226-231。
[2]埃里克·舒伯特,Jörg桑德,马丁·艾斯特,汉斯-彼得·克里格尔,徐晓伟,2017。“DBSCAN的再版,再版:为什么和如何使用DBSCAN”。ACM反式。数据库系统。42,3,第19条(2017年7月),21页。
[3] Dominik Kellner, Jens Klappstein和Klaus Dietmayer,“基于网格的DBSCAN聚类雷达数据扩展对象”,2012年IEEE智能汽车研讨会.
Thomas Wagner, Reinhard Feger和Andreas Stelzer,“一种基于网格的快速距离/多普勒/DoA测量聚类算法”,第十三届欧洲雷达会议论文集.
[5] Mihael Ankerst, Markus M. Breunig, Hans-Peter Kriegel, Jörg Sander,“光学:排序点识别聚类结构”,ACM SIGMOD ' 99 Int型。数据管理会议宾夕法尼亚州费城,1999年。
扩展功能
版本历史
介绍了R2021a
您也可以从以下列表中选择网站: