预测性维护,第2部分:用于识别状态指标的特征提取
在这个视频中,我们将讨论条件指示符,它们是什么,为什么它们很重要,以及如何选择它们。让我们从视觉练习开始。这两种形状有什么区别?看起来没有什么明显的区别,因为两个圆看起来几乎一样。然而,如果我们从不同的角度看它们,我们可以清楚地看到它们的区别,并可以识别它们是圆柱体和锥体。同样,当您查看来自机器的原始测量数据时,很难区分正常操作和故障操作。但是,使用条件指示器,我们能够从不同的角度查看数据,帮助我们区分健康和错误的操作。
您可以使用时间、频率和时频域特征从数据中导出条件指示器。时域特征包括均值、标准差、偏度和这里列出的其他特征。频域特征还可以作为状态指标,帮助诊断故障。例如,如果我们在时域内观察这台机器的振动数据,我们可以看到来自不同旋转部件的所有振动的综合效应。通过频域分析数据,我们可以隔离不同的振动源。峰值及其与标称值之间的变化可以指示故障的严重程度。这里是一些其他的频域特征,可以作为条件指示器。提取特征的另一种方法是在时频域查看数据,这有助于描述信号的频谱内容随时间的变化。有关其他功能,请查看视频描述中给出的链接。
这就是我们在之前的视频中讨论的预测性维护工作流。现在,我们将使用一个三缸泵的例子,并遵循这些步骤来识别也被称为特征的条件指示器。在继续之前,让我们澄清一下为什么我们真正需要这些特性。一旦我们确定了一些有用的特征,我们就用它们来训练机器学习模型。如果所选的特征集是好的,这意味着它们唯一地定义了健康的操作和不同的故障类型,当我们将新数据从机器输入到模型时,模型可以正确地估计机器的当前状态。然而,如果特征不明显,训练后的模型可能估计不准确。
让我们看看如何为泵提取一些有用的特征。这个动画展示了泵是如何工作的。电机转动曲轴,带动三个柱塞。液体从这里被吸到这里被排出这里的压力由传感器测量。在这种泵中可能出现的一些故障包括密封泄漏、入口堵塞和轴承磨损。这幅图显示了在稳定状态下采集的一秒钟的压力数据。它包括正常运行的测量,所有三种故障类型,以及它们的组合。我们首先需要预处理该数据,并将其转换为可以从中提取条件指示符的表单。原始数据有噪声,峰值达到传感器的最大值。它在时间上也被抵消即使测量的持续时间是相同的。 After cleaning up the noise and removing the offset, this is how the preprocessed data looks like. Now, this data includes all these conditions, but we can show them on separate plots to investigate different fault types and their combinations. The first thing we notice here is the cyclical behavior of the time-domain pressure signal. We can zoom in to better see what’s happening in each cycle. On each plot, the nominal values are shown with black, and the colored lines represent faulty operation. Now the question is: Can we distinguish the black line, the healthy operation, from the rest of the data on each plot, and can we also identify the unique differences between each set of colored lines? As you see here, the pressure data looks very similar for these two faults. Let’s use some of the time-domain features to identify condition indicators. Initially, you don’t know which features will do the best job of revealing the differences between fault types. Therefore, in this part you follow a trial-and-error method until you find some useful features you can work with. The first set of features that we’ll try are shown on the screen. One way to understand if these condition indicators can differentiate different types of faults is to investigate them using a boxplot.
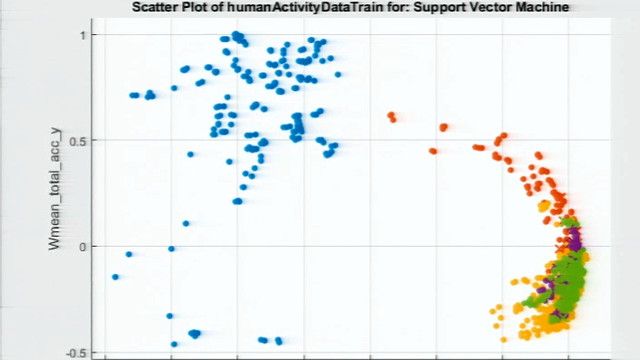
首先,我们将只看一个单一的特征,即平均值,对于健康状况和堵塞的进口故障。在图中,盒子没有重叠。这意味着这些数据组之间存在差异。利用该均值,可以很容易地将堵塞的进气道故障与健康状态区分开。然而,当我们不断添加其他故障类型的数据集时,情况就会发生变化。我们无法区分故障类型,因为其中一些是重叠的。如果我们对其他特征也尝试这种方法,我们最终会得到相同的结论:单个条件指示器不足以对错误行为进行分类,特别是当您有多个错误时。因此,现在我们要看两个特征的散点图,均值和方差。我们立即发现,有了两个条件指示器,我们可以更好地分离不同的故障。就像我们在这里所做的那样,您可以尝试不同的特征对,看看哪些特征在分类错误方面做得更好。
正如我们前面所讨论的,频域分析在分析周期数据和从具有旋转部件的机器获得的数据时非常重要。因此,现在我们将进一步研究我们的数据在频域,看看我们是否可以提取一些额外的特征。这些图之间的区别在于峰值和峰值频率,因此它们可以作为条件指标。让我们把时域分析用的图带回来。由于数据集的相似性,很难将这两个错误区分开来。但是现在从另一个角度看数据,我们看到在这个频率范围内的峰值将帮助我们成功地分离这两个断层。在选择了这些频域特征之后,我做了一个类似于我们对时域特征所做的分析。我观察到,所选择的特征是独特的,很适合训练机器学习模型。注意,当我们研究这些特征时,我们不仅要寻找不同的簇,而且还希望它们彼此之间的距离更远,因为这样训练过的模型可以更好地确定新数据点将属于哪个簇。
在提取条件指标后,可以用提取的特征训练机器学习模型,并可以用一个混淆矩阵来检验训练模型的准确性,就像这样。在对角线条目上,图显示了错误组合被正确预测的次数。非对角线的值表示错误的预测。
既然我们已经讨论了特征提取,您可能想知道有多少特征足够好来训练一个机器学习模型。不幸的是,我不能给你一个神奇的数字。你可能只有少数特征是与众不同的,而你真正理解得很好。但机器学习的美妙之处在于,它可以使用大量的特征来对数据进行分类。因此,您的模型可以从高维的特性集中受益。
在本视频中,我们讨论了条件指示器如何帮助我们区分健康状态和故障以及不同类型的故障。我们还展示了一个使用基于信号的方法提取条件指示符的示例。下一节,我们将讨论剩余使用寿命的估计。不要忘记查看下面的描述,了解更多关于如何使用MATLAB和Simulink开发预测性维护算法的资源和链接。