加权非线性回归
这个例子展示了如何对误差方差不恒定的数据拟合非线性回归模型。
当测量误差方差相等时,正则非线性最小二乘算法是合适的。当这个假设不成立时,使用加权拟合是合适的。方法使用权值fitnlm函数。
适合的数据和模型
我们将利用收集到的数据来研究工业和生活废物造成的水污染。这些数据在Box, g.p., W.G. Hunter和J.S. Hunter的《实验者的统计》(Wiley, 1978,第483-487页)中有详细描述。响应变量为生化需氧量(mg/l),预测变量为孵育时间(天)。
X = [1 2 3 5 7 10]';Y = [109 149 149 191 213 224]';情节(x, y,“柯”)包含(“孵化(天),x”) ylabel (生化需氧量(mg/l), y)

我们假设已知的是,前两个观测结果的精度低于其余观测结果。例如,它们可能是用不同的仪器制作的。对数据进行加权的另一个常见原因是,每个记录的观察结果实际上是在相同的x值下进行的几个测量值的平均值。在这里的数据中,假设前两个值代表一个原始测量值,而其余四个值分别是5个原始测量值的平均值。然后,根据每次观测的测量次数来计算权重是合适的。
W = [1 1 5 5 5 5]';
无权值拟合模型
我们将适合这些数据的模型是一个缩放指数曲线,当x变大时,它变得水平。
modelFun = @(b,x) b(1).*(1-exp(-b(2).*x));
根据粗略的视觉拟合,通过这些点绘制的曲线可能在x = 15附近的240左右趋于平稳。我们用240作为b1的起始值,因为e^(-。5*15)比1小,我们用。5作为b2的起始值。
Start = [240;5);
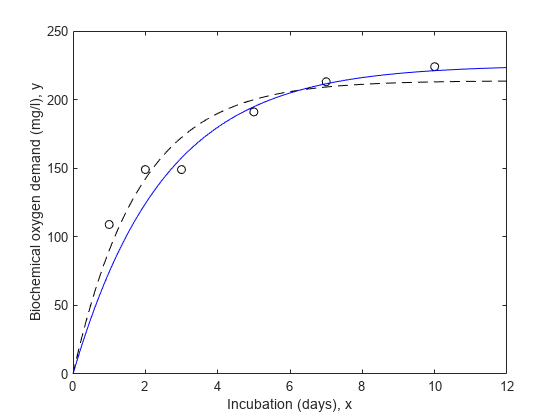
忽略测量误差的危险是,拟合可能受到不精确测量的过度影响,因此可能无法对精确已知的测量提供良好的拟合。让我们不带权值地拟合数据,并将其与点进行比较。
nlm = fitnlm(x,y,modelFun,开始);Xx = linspace(0,12)';线(xx,预测(nlm, xx),“线型”,“——”,“颜色”,“k”)

注意,拟合曲线被拉向前两个点,但似乎错过了其他点的趋势。
用权值拟合模型
让我们试着用重量来重复这个动作。
= fitnlm(x,y,modelFun,开始,“重量”w)
wnlm =非线性回归模型:y ~ b1*(1 - exp(- b2*x))估计系数:估计SE tStat pValue ________ ________ ______ __________ b1 225.17 10.7 21.045 3.0134e-05 b2 0.40078 0.064296 6.2333 0.0033745观察数:6,误差自由度:4均方根误差:24 r -平方:0.908,调整r -平方0.885 F-statistic vs.零模型:696,p-value = 8.2e-06
线(xx,预测(wnlm, xx),“颜色”,“b”)
在这种情况下,估计的总体标准差描述了权重或测量精度为1的“标准”观测结果的平均变化。
wnlm。RMSE
Ans = 24.0096
任何分析的一个重要部分是对模型拟合精度的估计。系数显示显示了参数的标准误差,但我们也可以为它们计算置信区间。
coefCI (wnlm)
ans =2×2195.4650 254.8788 0.2223 0.5793
估计响应曲线
接下来,我们将为它们计算拟合的响应值和置信区间。默认情况下,这些宽度是预测值的逐点置信边界,但我们将要求整个曲线的同步间隔。
[ypred,ypredci] = predict(wnlm,xx, xx,)“同时”,真正的);情节(x, y,“柯”xx ypred,“b -”xx ypredci,“:”)包含(“x”) ylabel (“y”ylim([-150 350]) legend({“数据”,“加权匹配”,“95%置信限度”},...“位置”,“东南”)

注意,这两个下加权的点并不像曲线上的其他点那样适合。这就是你所期望的加权匹配。
在x的特定值下估计未来观测的预测区间也是可能的。这些区间实际上假设权重或测量精度为1。
[ypred,ypredci] = predict(wnlm,xx, xx,)“同时”,真的,...“预测”,“观察”);情节(x, y,“柯”xx ypred,“b -”xx ypredci,“:”)包含(“x”) ylabel (“y”ylim([-150 350]) legend({“数据”,“加权匹配”,“95%预测极限”},...“位置”,“东南”)

权重的绝对比例实际上并不影响参数估计。将权重乘以任意常数都可以得到相同的估计值。但它们确实会影响置信边界,因为边界代表权重为1的观察结果。在这里您可以看到,与置信极限相比,权重较高的点似乎太接近拟合线。
假设我们对一个基于五次测量的平均值的新观测结果感兴趣,就像这个图中的最后四个点一样。方法指定观察权重权重的名称-值参数预测函数。
[new_ypred, new_ypreci] = predict(wnlm,xx,)“同时”,真的,...“预测”,“观察”,“重量”5 *的(大小(xx)));情节(x, y,“柯”xx new_ypred,“b -”xx new_ypredci,“:”)包含(“x”) ylabel (“y”ylim([-150 350]) legend({“数据”,“加权匹配”,“95%预测极限”},...“位置”,“东南”)

的预测函数估计了观测时的误差方差我通过MSE * (1 / W (i)),在那里均方误差是均方误差。因此,置信区间变窄。
残留分析
除了绘制数据和拟合之外,还绘制从拟合到预测因子的残差,以诊断模型中的任何问题。残差应该表现为独立和同分布(i.i.d.),但方差与权重的倒数成正比。绘制标准化残差图,以确认这些值具有相同的方差。标准化残差是原始残差除以估计标准差。
r = wnlm. residual . standardization;情节(x, r,“b ^”)包含(“x”) ylabel (标准化残差的)

在这个残差图中有一些系统模式的证据。注意后四个残差是如何具有线性趋势的,这表明模型可能不会随着x的增加而增长得足够快。此外,残差的大小随着x的增加趋于减小,这表明测量误差可能取决于x。这些值得研究,然而,数据点太少,很难对这些明显的模式给予重视。
另请参阅
您也可以从以下列表中选择网站: