基于超参数优化的分类学习者应用程序训练分类器
这个例子展示了如何在分类学习者应用程序中使用超参数优化来调优分类支持向量机(SVM)模型的超参数。比较经过训练的可优化支持向量机的测试集性能与性能最好的预置支持向量机模型的测试集性能。
在MATLAB®命令窗口,加载
电离层数据集,并创建一个包含数据的表。负载电离层台= array2table (X);资源描述。Y= Y;开放分类学习者。单击应用程序选项卡,然后单击右侧的箭头应用程序部分打开应用程序库。在机器学习和深度学习组中,单击分类学习者.
在分类学习者选项卡,文件部分中,选择从工作区新建会话>.
在“从工作区新建会话”对话框中,选择
资源描述从数据集变量列表。应用程序选择响应和预测变量。默认响应变量为Y.默认的验证选项是5倍交叉验证,以防止过拟合。在测试节中,单击复选框以留出测试数据集。指定使用
15作为测试集的导入数据的百分比。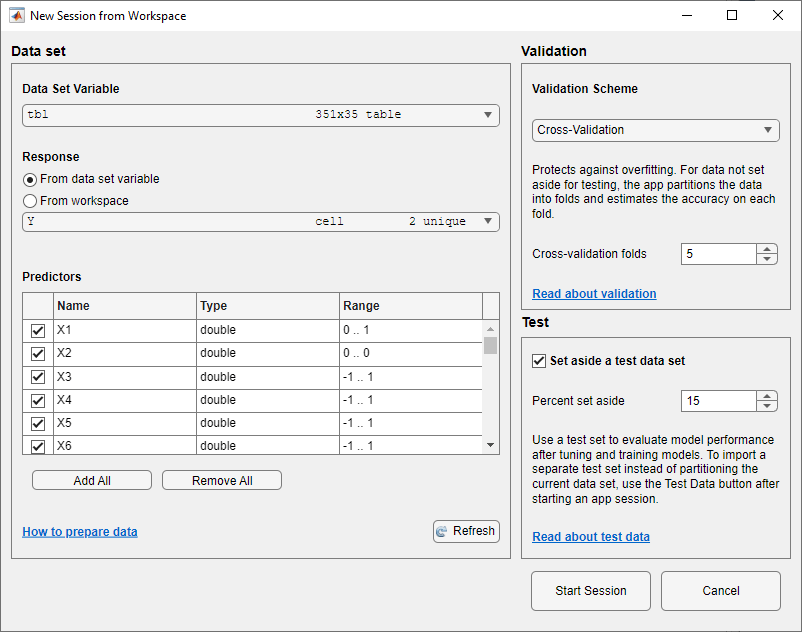
要接受选项并继续,请单击开始会议.
训练所有预设的SVM模型。在分类学习者选项卡,模型部分,单击箭头打开图库。在支持向量机组中,单击所有支持向量机.在火车部分中,点击火车都并选择火车都.该应用程序训练每种SVM模型类型中的一种,以及默认的精细树模型,并在模型窗格。
请注意
如果您有并行计算工具箱™,那么应用程序有使用并行按钮默认开启。你点击后火车都并选择火车都或选择火车,该应用程序会打开一个平行的工人池。在此期间,您不能与软件交互。池打开后,您可以继续与应用程序交互,同时模型并行训练。
如果没有并行计算工具箱,则应用程序具有使用背景培训的复选框。火车都默认选择的菜单。在你选择一个训练模型的选项后,应用程序会打开一个后台池。池打开后,当模型在后台训练时,您可以继续与应用程序交互。
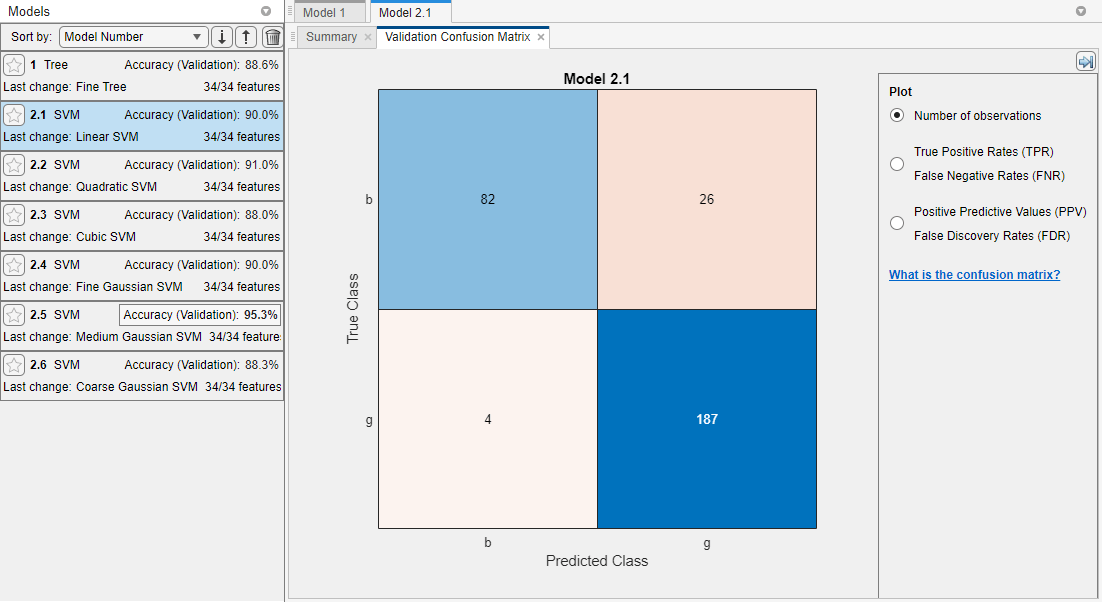
该应用程序显示第一个支持向量机模型(模型2.1)的验证混淆矩阵。蓝色值表示正确的分类,红色值表示错误的分类。的模型左边的窗格显示了每个模型的验证精度。
请注意
验证在结果中引入了一些随机性。您的模型验证结果可能与此示例中显示的结果不同。
选择一个可优化的支持向量机模型进行训练。在分类学习者选项卡,模型部分,单击箭头打开图库。在支持向量机组中,单击Optimizable支持向量机.
选择要优化的模型超参数。在总结选项卡,您可以选择优化选中要优化的超参数的复选框。默认情况下,选中可用超参数的所有复选框。对于本例,清除优化复选框的核函数而且标准化数据.默认情况下,应用程序禁用优化复选框的内核规模每当核函数有一个固定的值,而不是
高斯.选择一个高斯核函数,并选择优化复选框的内核规模.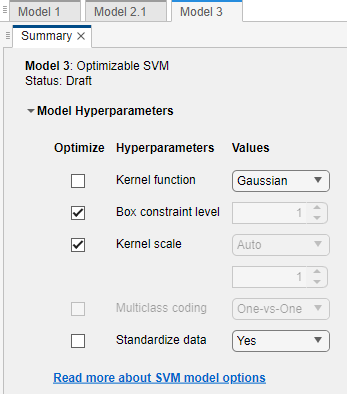
训练可优化模型。在火车部分的分类学习者选项卡上,单击火车都并选择选择火车.
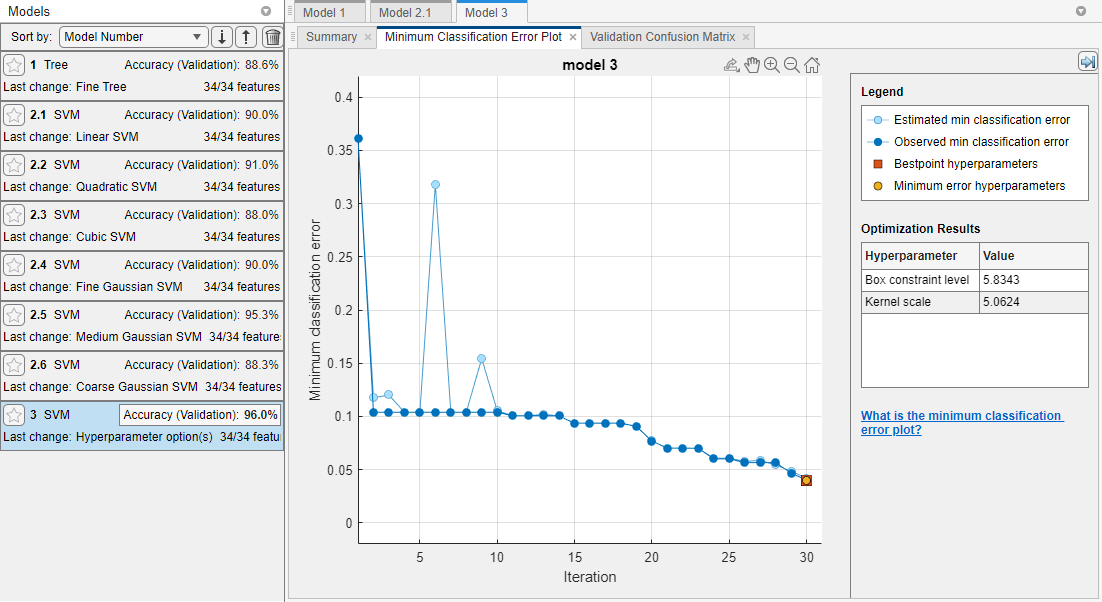
应用程序显示一个最小分类误差图因为它运行优化过程。在每次迭代中,应用程序都会尝试不同的超参数值组合,并使用到该迭代为止观察到的最小验证分类错误(用深蓝色表示)更新绘图。当应用程序完成优化过程时,它会选择优化后的超参数集,用红色方块表示。有关更多信息,请参见最小分类误差图.
该应用程序列出了优化的超参数优化结果Section的右边是plot和可优化的支持向量机模型超参数模型截面总结选项卡。
请注意
一般情况下,优化结果是不可重复的。
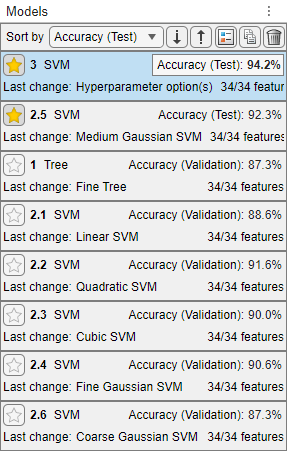
将训练过的预设支持向量机模型与训练过的可优化模型进行比较。在模型窗格,应用程序高亮显示最高准确性(验证)在一个盒子里勾勒出来。在本例中,训练过的可优化SVM模型优于六个预设模型。
经过训练的可优化模型并不总是比经过训练的预设模型具有更高的精度。如果一个经过训练的可优化模型不能很好地执行,您可以尝试通过运行更长的优化时间来获得更好的结果。在分类学习者选项卡,选项部分中,点击优化器.在对话框中,增加迭代价值。例如,可以双击的默认值
30.并输入值60.然后单击保存和应用.方法创建的未来可优化模型将应用这些选项模型画廊。因为超参数调优常常导致模型过拟合,所以在测试集上检查可优化的SVM模型的性能,并将其与最佳预置的SVM模型的性能进行比较。在将数据导入应用程序时,使用为测试保留的数据。
首先,在模型窗格中,单击控件旁边的星形图标介质高斯支持向量机模型和Optimizable支持向量机模型。
中选择每个模型模型窗格。在测试部分的分类学习者选项卡上,单击测试所有然后选择测试选择.该应用程序计算在其余数据(即训练和验证数据)上训练的模型的测试集性能。
根据测试集精度对模型进行排序。在模型窗格中,打开排序列表并选择
准确性(测试).在本例中,经过训练的可优化模型在测试集数据上仍然优于经过训练的预设模型。然而,这两个模型的测试精度都没有验证精度高。
直观地比较模型的测试集性能。对于每个带星号的模型,在模型窗格。在分类学习者选项卡,情节和解释部分,单击箭头打开图库,然后单击混淆矩阵(测试)在测试结果组。
重新排列这些图的布局,以便更好地进行比较。首先,关闭所有模型的plot和summary选项卡2.5模型而且模型3.然后,在情节和解释部分,单击布局按钮并选择比较模型.单击隐藏情节选项按钮
 在地块的右上方,为地块腾出更多空间。
在地块的右上方,为地块腾出更多空间。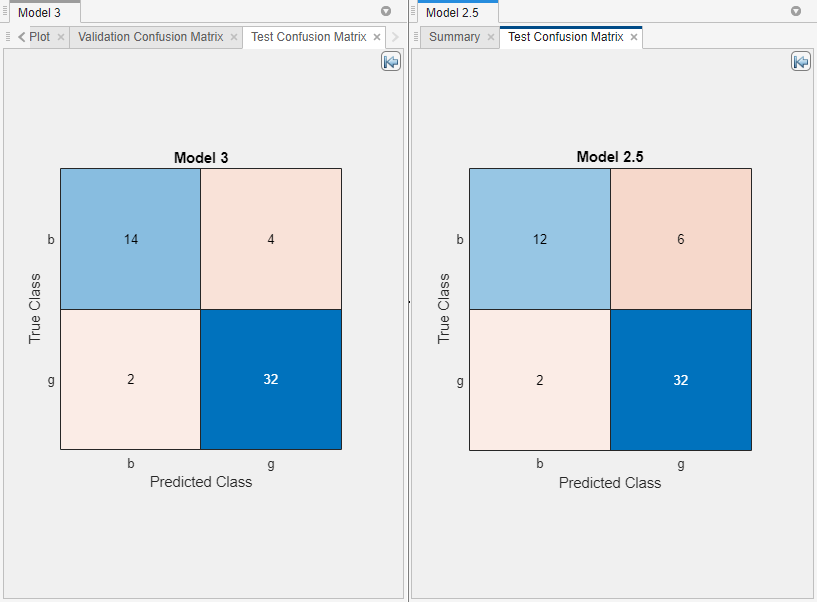
若要返回原始布局,可单击布局按钮并选择单一模式(默认).






相关的话题
您也可以从以下列表中选择网站: