利用模型函数的列车网络
这个例子展示了如何使用函数来创建和训练一个深度学习网络,而不是使用层图或dlnetwork.使用函数的优点是可以灵活地描述各种各样的网络。缺点是您必须完成更多的步骤并仔细准备数据。这个示例使用了手写数字的图像,有两个目标:对数字进行分类和确定每个数字与垂直方向的角度。
负荷训练数据
的digitTrain4DArrayData函数从垂直方向加载图像、它们的数字标签以及它们的旋转角度。创建arrayDatastore对象获取图像、标签和角度,然后使用结合函数生成包含所有训练数据的单个数据存储。提取类名和非离散响应的数量。
[XTrain, T1Train T2Train] = digitTrain4DArrayData;dsXTrain = arrayDatastore (XTrain IterationDimension = 4);dsT1Train = arrayDatastore (T1Train);dsT2Train = arrayDatastore (T2Train);dsTrain =结合(dsXTrain dsT1Train dsT2Train);一会=类别(T1Train);numClasses =元素个数(类名);numResponses =大小(T2Train, 2);numObservations =元素个数(T1Train);
从训练数据中查看一些图像。
idx = randperm (numObservations, 64);我= imtile (XTrain (:,:,:, idx));图imshow(我)

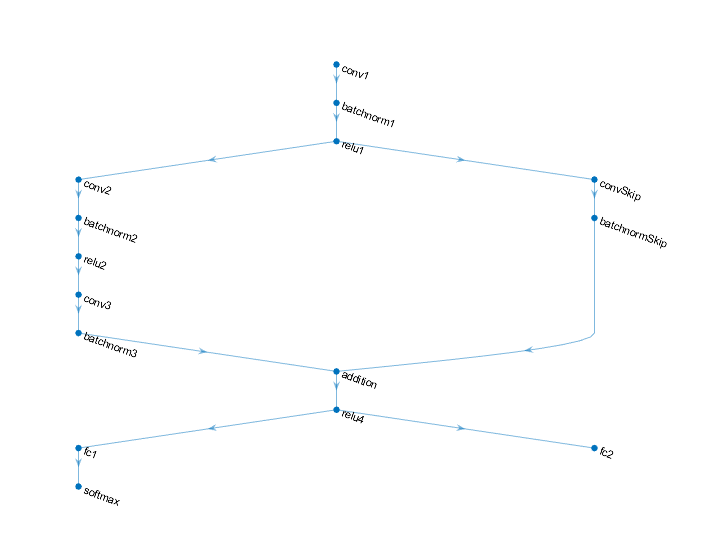
定义深度学习模型
定义以下预测标签和旋转角度的网络。
卷积-batchnorm- relu块,包含16个5 × 5滤波器。
两个卷积-批量范数块的分支,每个块都有32个3乘3过滤器,中间有一个ReLU操作
一个带有32个1乘1卷积的卷积-batchnorm块的跳过连接。
使用加法和ReLU操作合并两个分支
对于回归输出,具有大小为1(响应的数量)的全连接操作的分支。
对于分类输出,一个分支具有大小为10(类的数量)的全连接操作和一个softmax操作。
定义和初始化模型参数和状态
为每个操作定义参数,并将它们包含在结构中。使用格式parameters.OperationName.ParameterName在哪里参数是结构,哦perationName操作的名称(例如“conv1”)和ParameterName是参数的名称(例如,“Weights”)。
创建一个结构参数包含模型参数。方法初始化可学习的权重和偏差initializeGlorot而且initializeZeros例子函数,分别。方法初始化批归一化偏移量和缩放参数initializeZeros而且initializeOnes例子函数,分别。
要使用批处理规范化操作执行训练和推断,还必须管理网络状态。在进行预测之前,必须指定从训练数据导出的数据集均值和方差。创建一个结构状态包含状态参数。批处理规范化统计信息不能dlarray对象。方法初始化批归一化训练的均值和训练的方差状态0而且的函数,分别。
初始化示例函数作为支持文件附加到这个示例中。
初始化第一个卷积操作“conv1”的参数。
filterSize = [5 5];numChannels = 1;numFilters = 16;sz = [filterSize numChannels numFilters];numOut = prod(filterSize) * numFilters;numIn = prod(filterSize) * numFilters;parameters.conv1。重量= initializeGlorot(深圳、numOut numIn);parameters.conv1。Bias = initializeZeros([numFilters 1]);
初始化第一批规范化操作“batchnorm1”的参数和状态。
parameters.batchnorm1。偏移量= initializeZeros([numFilters 1]);parameters.batchnorm1。Scale = initializeOnes([numFilters 1]);state.batchnorm1。TrainedMean = initializeZeros([numFilters 1]);state.batchnorm1。TrainedVariance = initializeOnes([numFilters 1]);
初始化第二个卷积操作“conv2”的参数。
filterSize = [3 3];numChannels = 16;numFilters = 32;sz = [filterSize numChannels numFilters];numOut = prod(filterSize) * numFilters;numIn = prod(filterSize) * numFilters;parameters.conv2。重量= initializeGlorot(深圳、numOut numIn);parameters.conv2。Bias = initializeZeros([numFilters 1]);
初始化第二个批处理规范化操作“batchnorm2”的参数和状态。
parameters.batchnorm2。偏移量= initializeZeros([numFilters 1]);parameters.batchnorm2。Scale = initializeOnes([numFilters 1]);state.batchnorm2。TrainedMean = initializeZeros([numFilters 1]);state.batchnorm2。TrainedVariance = initializeOnes([numFilters 1]);
初始化第三个卷积操作“conv3”的参数。
filterSize = [3 3];numChannels = 32;numFilters = 32;sz = [filterSize numChannels numFilters];numOut = prod(filterSize) * numFilters;numIn = prod(filterSize) * numFilters;parameters.conv3。重量= initializeGlorot(深圳、numOut numIn);parameters.conv3。Bias = initializeZeros([numFilters 1]);
初始化第三批规范化操作“batchnorm3”的参数和状态。
parameters.batchnorm3。偏移量= initializeZeros([numFilters 1]);parameters.batchnorm3。Scale = initializeOnes([numFilters 1]);state.batchnorm3。TrainedMean = initializeZeros([numFilters 1]);state.batchnorm3。TrainedVariance = initializeOnes([numFilters 1]);
在跳过连接“convSkip”中初始化卷积操作的参数。
filterSize = [1 1];numChannels = 16;numFilters = 32;sz = [filterSize numChannels numFilters];numOut = prod(filterSize) * numFilters;numIn = prod(filterSize) * numFilters;parameters.convSkip.Weights = initializeGlorot(深圳、numOut numIn);parameters.convSkip.Bias = initializeZeros([numFilters 1]);
在跳过连接“batchnormSkip”中初始化批处理规范化操作的参数和状态。
parameters.batchnormSkip.Offset = initializeZeros([numFilters 1]);parameters.batchnormSkip.Scale = initializeOnes([numFilters 1]);state.batchnormSkip.TrainedMean = initializeZeros([numFilters 1]);state.batchnormSkip.TrainedVariance = initializeOnes([numFilters 1]);
初始化与分类输出“fc1”对应的全连接操作的参数。
sz = [numClasses 6272];numOut = numClasses;numIn = 6272;parameters.fc1。重量= initializeGlorot(深圳、numOut numIn);parameters.fc1。Bias = initializeZeros([numClasses 1]);
初始化与回归输出“fc2”对应的全连接操作的参数。
sz = [numResponses 6272];numOut = numResponses;numIn = 6272;parameters.fc2。重量= initializeGlorot(深圳、numOut numIn);parameters.fc2。Bias = initializeZeros([numResponses 1]);
查看参数的结构。
参数
参数=结构体字段:conv1:(1×1结构)batchnorm1:[1×1 struct] conv2:[1×1 struct] batchnorm2:[1×1 struct] conv3:[1×1 struct] batchnorm3:[1×1 struct] convSkip:[1×1 struct] batchnormSkip:[1×1 struct] fc1:[1×1 struct] fc2:[1×1 struct]
查看“conv1”操作的参数。
parameters.conv1
ans =结构体字段:权重:[5×5×1×16 dlarray]偏差:[16×1 dlarray]
查看状态参数的结构。
状态
状态=结构体字段:batchnorm1: [1×1 struct] batchnorm2: [1×1 struct] batchnorm3: [1×1 struct] batchnormSkip: [1×1 struct]
查看“batchnorm1”的状态参数。
state.batchnorm1
ans =结构体字段:TrainedMean: [16×1 dlarray]训练方差:[16×1 dlarray]
定义模型函数
创建函数模型,它计算前面描述的深度学习模型的输出。
这个函数模型取模型参数参数,输入数据,标志doTraining它指定模型是否应该返回用于训练或预测的输出,以及网络状态。网络输出标签的预测、角度的预测和更新的网络状态。
定义模型损失函数
创建函数modelLoss,它接受模型参数、带有包含标签和角度的对应目标的小批输入数据,并返回损耗、损耗相对于可学习参数的梯度和更新的网络状态。
指定培训选项
指定培训选项。训练20个周期,小批次大小为128。
numEpochs = 20;miniBatchSize = 128;
火车模型
使用minibatchqueue处理和管理小批量的图像。为每个mini-batch:
使用自定义的小批量预处理功能
preprocessMiniBatch(在本例末尾定义)对类标签进行一次性编码。用尺寸标签格式化图像数据
“SSCB”(空间,空间,渠道,批处理)。默认情况下,minibatchqueue对象将数据转换为dlarray具有基础类型的对象单.不要为类标签或角度添加格式。如果有GPU,请使用GPU进行训练。默认情况下,
minibatchqueue对象将每个输出转换为gpuArray如果有可用的GPU。使用GPU需要并行计算工具箱™和支持的GPU设备。有关支持的设备的信息,请参见GPU计算的需求(并行计算工具箱).
兆贝可= minibatchqueue (dsTrain,...MiniBatchSize = MiniBatchSize,...MiniBatchFcn = @preprocessMiniBatch,...MiniBatchFormat = [“SSCB”""""]);
对于每个历元,洗牌数据并遍历小批数据。在每次迭代结束时,显示训练进度。为每个mini-batch:
评估模型损失和梯度
dlfeval和modelLoss函数。更新网络参数
adamupdate函数。
初始化Adam的参数。
trailingAvg = [];trailingAvgSq = [];
初始化训练进度图。
图C = colororder;lineLossTrain = animatedline(颜色= C (2:));ylim([0正])包含(“迭代”) ylabel (“损失”网格)在
火车模型。
迭代= 0;开始=抽搐;循环遍历各个时代。为时代= 1:numEpochs%洗牌数据。洗牌(兆贝可)在小批量上循环而Hasdata (mbq)迭代=迭代+ 1;[X, T1, T2] =下一个(兆贝可);评估模型损失,梯度和状态,使用dlfeval和% modelLoss函数。(损失、渐变、状态)= dlfeval (@modelLoss、参数X, T1, T2,状态);使用Adam优化器更新网络参数。(参数、trailingAvg trailingAvgSq) = adamupdate(参数、渐变...trailingAvg trailingAvgSq,迭代);显示培训进度。D =持续时间(0,0,toc(开始),格式=“hh: mm: ss”);=双重损失(损失);addpoints (lineLossTrain、迭代、失去)标题(”时代:“+时代+”,过去:“+ drawnow字符串(D))结束结束

测试模型
通过将测试集上的预测与真实的标签和角度进行比较,来测试模型的分类精度。方法管理测试数据集minibatchqueue对象,使用与训练数据相同的设置。
[XTest, T1Test T2Test] = digitTest4DArrayData;dsXTest = arrayDatastore (XTest IterationDimension = 4);dsT1Test = arrayDatastore (T1Test);dsT2Test = arrayDatastore (T2Test);dst =结合(dsXTest dsT1Test dsT2Test);mbqTest = minibatchqueue (dst,...MiniBatchSize = MiniBatchSize,...MiniBatchFcn = @preprocessMiniBatch,...MiniBatchFormat = [“SSCB”""""]);
为了预测验证数据的标签和角度,循环遍历小批次并使用模型函数doTraining选项设置为假.存储预测的类和角度。比较预测的和真实的类和角度,并存储结果。
doTraining = false;classesPredictions = [];anglesPredictions = [];classCorr = [];angleDiff = [];在小批量上循环。而hasdata (mbqTest)读取小批数据。[X, T1, T2] =下一个(mbqTest);使用predict函数进行预测。(Y1, Y2) =模型(参数X, doTraining状态);确定预测的类。日元= onehotdecode (Y1,一会,1);classesforecasts = [classesforecasts Y1];德明预测角度Y2 = extractdata (Y2);anglesforecasts = [anglesforecasts Y2];比较预测类和真实类Y1Test = onehotdecode (T1,一会,1);classCorr = [classCorr Y1 == Y1Test];比较预测角度和真实角度angleDiffBatch = Y2 - T2;angleDiff = [angleDiff extractdata(gather(angleDiffBatch))];结束
评估分类的准确性。
精度=意味着(classCorr)
精度= 0.9712
评估回归精度。
angleRMSE =√意味着(angleDiff ^ 2))
angleRMSE =单6.7999
查看一些带有预测的图片。红色显示预测的角度,绿色显示正确的标签。
idx = randperm(大小(XTest, 4), 9);数字为i = 1:9 subplot(3,3,i) i = XTest(:,:,:,idx(i));imshow (I)在深圳=大小(我,1);抵消= sz / 2;thetaPred = anglesPredictions (idx (i));情节(抵消* [1-tand (thetaPred) 1 +罐内(thetaPred)], [sz 0],“r——”thetavalylation = T2Test(idx(i));情节(抵消* [1-tand (thetaValidation) 1 +罐内(thetaValidation)], [sz 0],“g——”)举行从标签=字符串(classesPredictions (idx (i)));标题(”的标签:“+标签)结束

模型函数
这个函数模型取模型参数参数,输入数据X的国旗doTraining它指定模型是否应该返回用于训练或预测的输出,以及网络状态状态.网络输出标签的预测、角度的预测和更新的网络状态。

函数(Y1、Y2、状态)=模型(参数X, doTraining状态)%初始操作卷积- conv1重量= parameters.conv1.Weights;偏见= parameters.conv1.Bias;Y = dlconv (X,重量、偏见、填充=“相同”);批处理归一化,ReLU - batchnorm1, relu1抵消= parameters.batchnorm1.Offset;规模= parameters.batchnorm1.Scale;trainedMean = state.batchnorm1.TrainedMean;trainedVariance = state.batchnorm1.TrainedVariance;如果doTraining [Y,trainedMean,trainedVariance] = batchnorm(Y,offset,scale,trainedMean,trainedVariance);%更新状态state.batchnorm1。TrainedMean = TrainedMean;state.batchnorm1。TrainedVariance = TrainedVariance;其他的Y = batchnorm (Y,抵消,规模、trainedMean trainedVariance);结束Y = relu (Y);%主要分支业务卷积- conv2重量= parameters.conv2.Weights;偏见= parameters.conv2.Bias;YnoSkip = dlconv (Y,重量、偏见、填充=“相同”,步= 2);批处理归一化,ReLU - batchnorm2, relu2抵消= parameters.batchnorm2.Offset;规模= parameters.batchnorm2.Scale;trainedMean = state.batchnorm2.TrainedMean;trainedVariance = state.batchnorm2.TrainedVariance;如果doTraining [noskip,trainedMean,trainedVariance] = batchnorm(YnoSkip,offset,scale,trainedMean,trainedVariance);%更新状态state.batchnorm2。TrainedMean = TrainedMean;state.batchnorm2。TrainedVariance = TrainedVariance;其他的YnoSkip = batchnorm (YnoSkip、抵消、规模、trainedMean trainedVariance);结束YnoSkip = relu (YnoSkip);卷积- conv3重量= parameters.conv3.Weights;偏见= parameters.conv3.Bias;YnoSkip = dlconv (YnoSkip、重量、偏见、填充=“相同”);批处理规范化- batchnorm3 . %抵消= parameters.batchnorm3.Offset;规模= parameters.batchnorm3.Scale;trainedMean = state.batchnorm3.TrainedMean;trainedVariance = state.batchnorm3.TrainedVariance;如果doTraining [noskip,trainedMean,trainedVariance] = batchnorm(YnoSkip,offset,scale,trainedMean,trainedVariance);%更新状态state.batchnorm3。TrainedMean = TrainedMean;state.batchnorm3。TrainedVariance = TrainedVariance;其他的YnoSkip = batchnorm (YnoSkip、抵消、规模、trainedMean trainedVariance);结束%跳过连接操作卷积,批处理归一化(跳过连接)- convSkip, batchnormSkip重量= parameters.convSkip.Weights;偏见= parameters.convSkip.Bias;YSkip = dlconv (Y,重量、偏见、步幅= 2);抵消= parameters.batchnormSkip.Offset;规模= parameters.batchnormSkip.Scale;trainedMean = state.batchnormSkip.TrainedMean;trainedVariance = state.batchnormSkip.TrainedVariance;如果doTraining [YSkip,trainedMean,trainedVariance] = batchnorm(YSkip,offset,scale,trainedMean,trainedVariance);%更新状态state.batchnormSkip.TrainedMean = trainedMean;state.batchnormSkip.TrainedVariance = trainedVariance;其他的YSkip = batchnorm (YSkip、抵消、规模、trainedMean trainedVariance);结束%的最后操作%添加,ReLU -添加,relu4Y = skip + YnoSkip;Y = relu (Y);%完全连接,softmax(标签)- fc1, softmax重量= parameters.fc1.Weights;偏见= parameters.fc1.Bias;日元= fullyconnect (Y,重量,偏差);日元= softmax (Y1);%完全连接(角度)- fc2重量= parameters.fc2.Weights;偏见= parameters.fc2.Bias;Y2 = fullyconnect (Y,重量,偏差);结束
损失函数模型
的modelLoss函数,接受模型参数,一个小批量的输入数据X与相应的目标T1而且T2分别包含标签和角度,并返回损耗、损耗相对于可学习参数的梯度和更新的网络状态。
函数[loss,gradient,state] = modelLoss(parameters,X,T1,T2,state) doTraining = true;(Y1、Y2、状态)=模型(参数X, doTraining状态);lossLabels = crossentropy (Y1, T1);lossAngles = mse (Y2, T2);loss = lossLabels + 0.1*lossAngles;梯度= dlgradient(损失、参数);结束
Mini-Batch预处理功能
的preprocessMiniBatch函数使用以下步骤对数据进行预处理:
从传入的单元格数组中提取图像数据并连接到数字数组中。将第四个维度上的图像数据连接起来,将为每个图像添加第三个维度,用作单例通道维度。
从传入单元格数组中提取标签和角度数据,并沿二次元分别连接到类别数组和数值数组。
一热编码类别标签到数字数组。对第一个维度进行编码会生成一个与网络输出形状匹配的编码数组。
函数[X, T1, T2] = preprocessMiniBatch (dataX、dataT1 dataT2)从单元格中提取图像数据并连接猫(X = 4, dataX {:});从单元格中提取标签数据并连接T1 =猫(2,dataT1 {:});从单元格中提取角度数据并连接。T2 =猫(2,dataT2 {:});单热编码标签T1 = onehotencode (T1, 1);结束
另请参阅
dlarray|sgdmupdate|dlfeval|dlgradient|fullyconnect|dlconv|softmax|线性整流函数(Rectified Linear Unit)|batchnorm|crossentropy|minibatchqueue|onehotencode|onehotdecode
相关的话题
您也可以从以下列表中选择网站: