音频的机器学习和深度学习
数据集管理、标记和扩充;音频、语音和声学应用的分割和特征提取
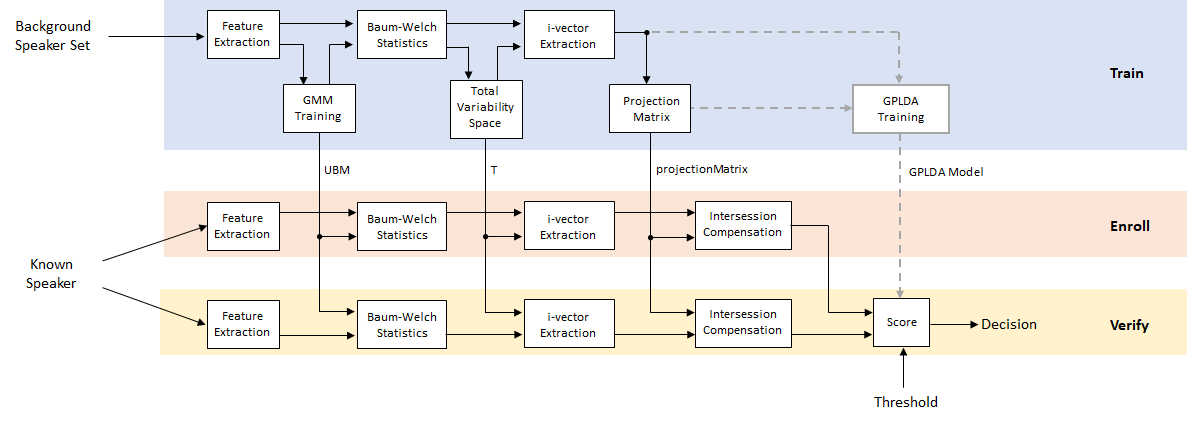
Audio Toolbox™提供了为音频、语音和声学应用开发机器和深度学习解决方案的功能,包括说话人识别、语音命令识别、声学场景识别等。
使用
audioDatastore吸收大量音频数据集并并行处理文件。使用信号贴标签机通过手动和自动标注音频记录来构建音频数据集。
使用
audioDataAugmenter为增强和合成音频数据集创建内置或自定义信号处理方法的随机管道。使用
audioFeatureExtractor在共享中间计算的同时提取不同特征的组合。
Audio Toolbox还提供对文本到语音和语音到文本的第三方api的访问,它包括预先训练的VGGish和YAMNet模型,以便您可以执行迁移学习、分类声音和提取特征嵌入。使用预先训练的网络需要深度学习工具箱™。
类别
- 数据集管理和标记
摄取、创建和标记大型数据集 - 特征提取
梅尔谱图,MFCC,音高,谱描述符 - 数据增加
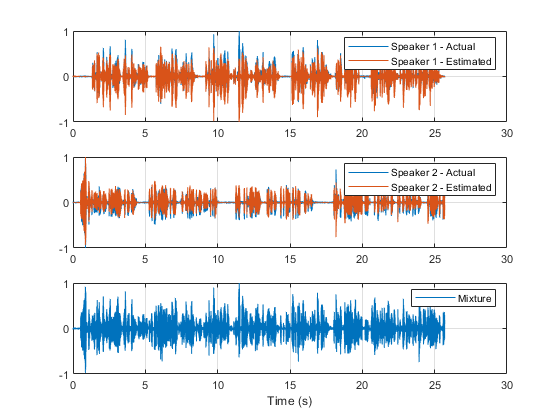
增加管道,移位音调和时间,拉伸时间,控制音量和噪声 - 分割
检测和隔离语音和其他声音 - Pretrained模型
转移学习,声音分类,特征嵌入,预训练音频深度学习网络 - 语音转录与合成
为文本到语音和语音到文本使用预先训练的模型或第三方api - 代码生成和GPU支持
生成可移植的C/ c++ /MEX函数,并使用gpu部署或加速处理
特色的例子
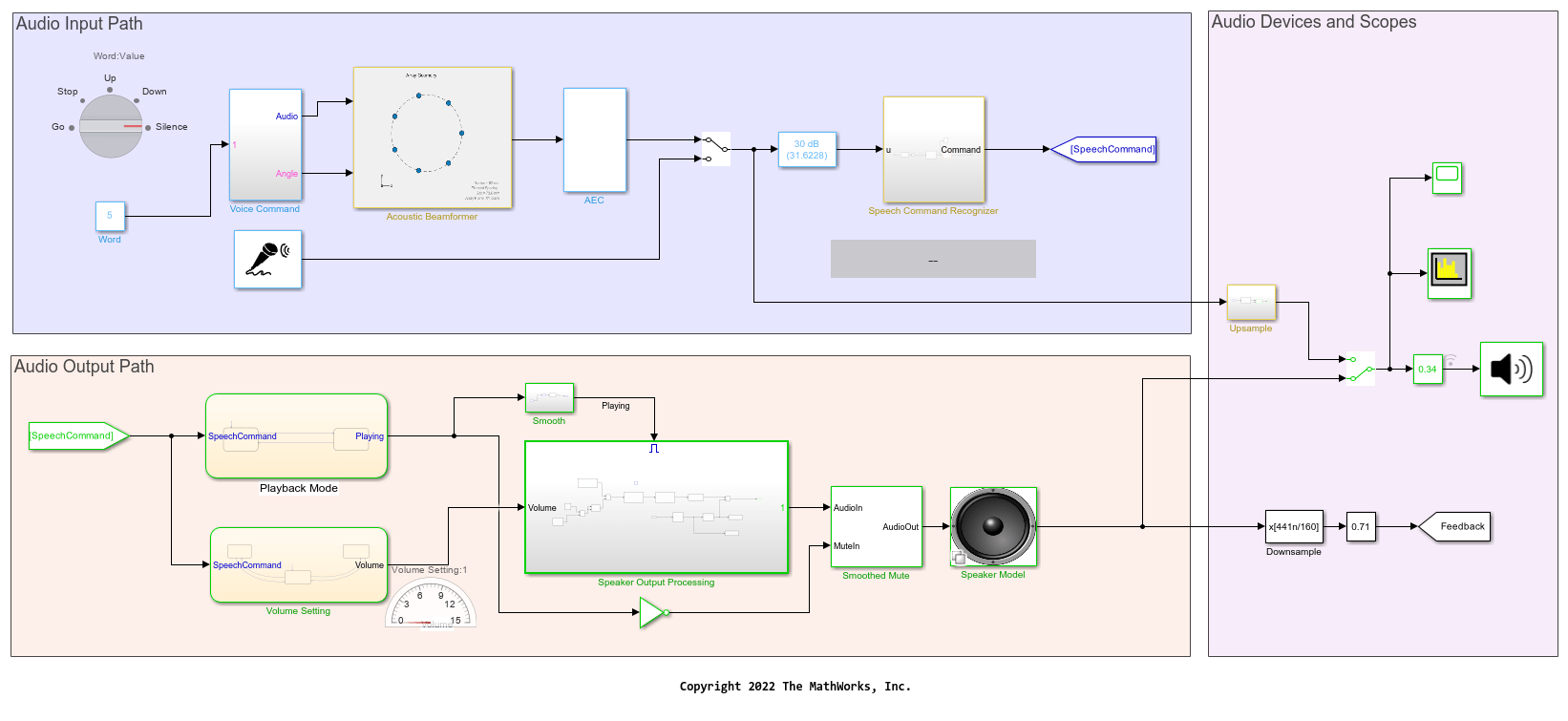

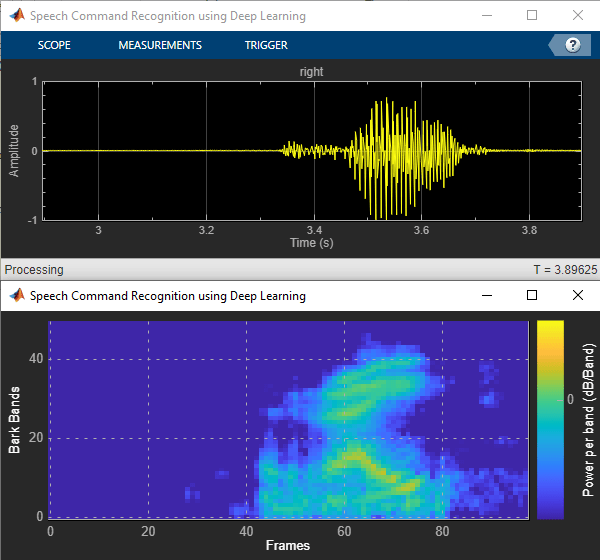
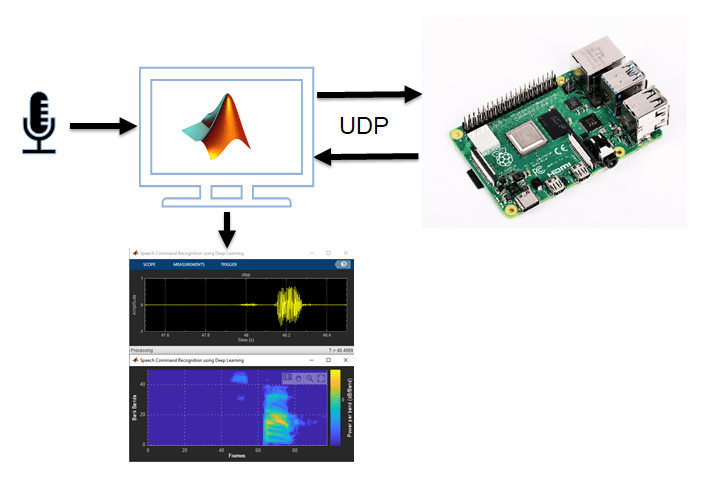
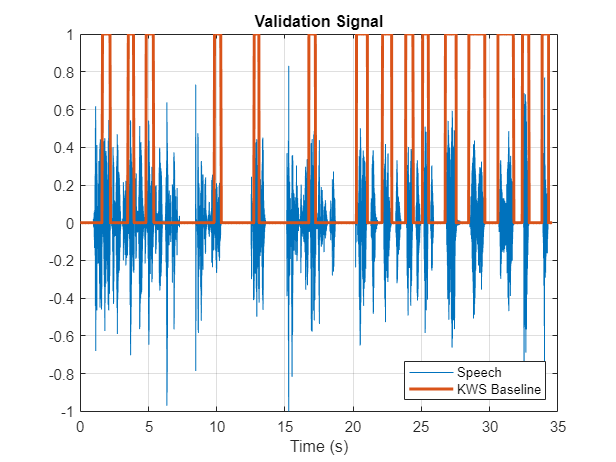
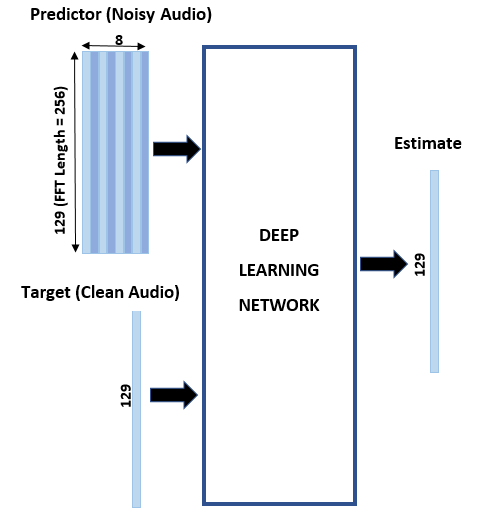
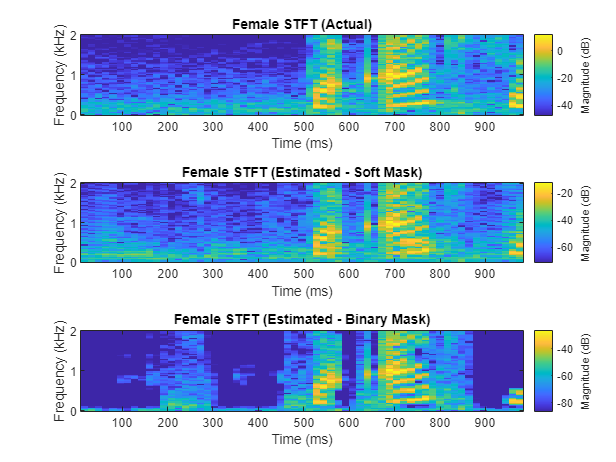
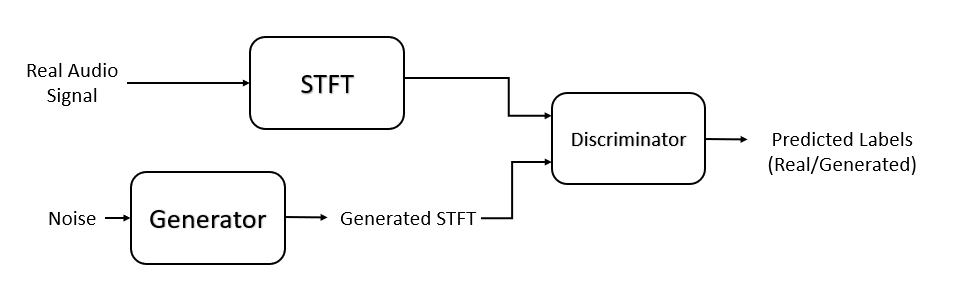
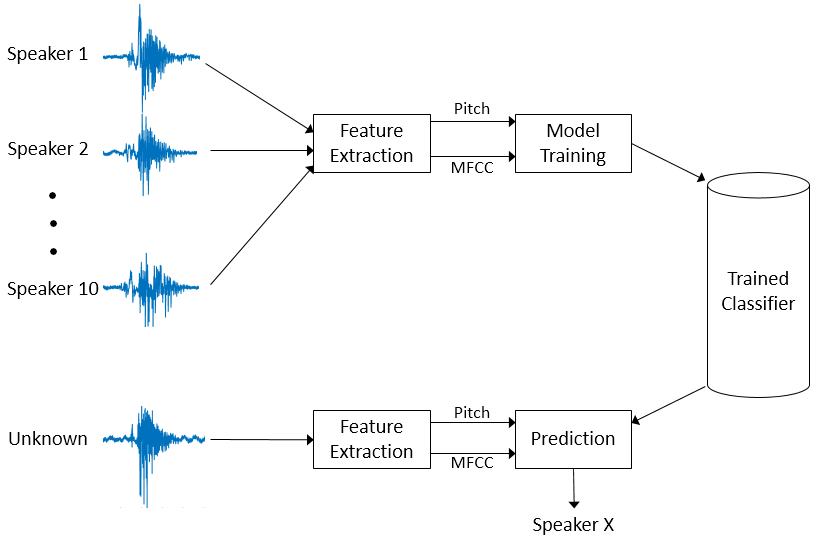
您也可以从以下列表中选择网站: